 SudhaData & BI Addict
SudhaData & BI Addict
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
Editor’s Note: In an era where there is a tool for everything right from data warehousing, data analytics, business intelligence, etc. the key problem arises in integrating all of them. That’s what Data Fabric solves. Know more about data fabric, what the key features are, and how to get started with it in this article.
What if there was a team consisting of players like Michael Jordan, LeBron James, Magic Johnson, Larry Bird, Shaquille O'Neal, Kobe Bryant, etc.? Even the thought sounds very exciting, isn’t it?
Now think about the same for your data management - what if there was a way to combine data lake, data analysis, AI, and visualizations? That’s what Microsoft Fabric does. We’ll explore what key players are involved in this and what their contributions are.
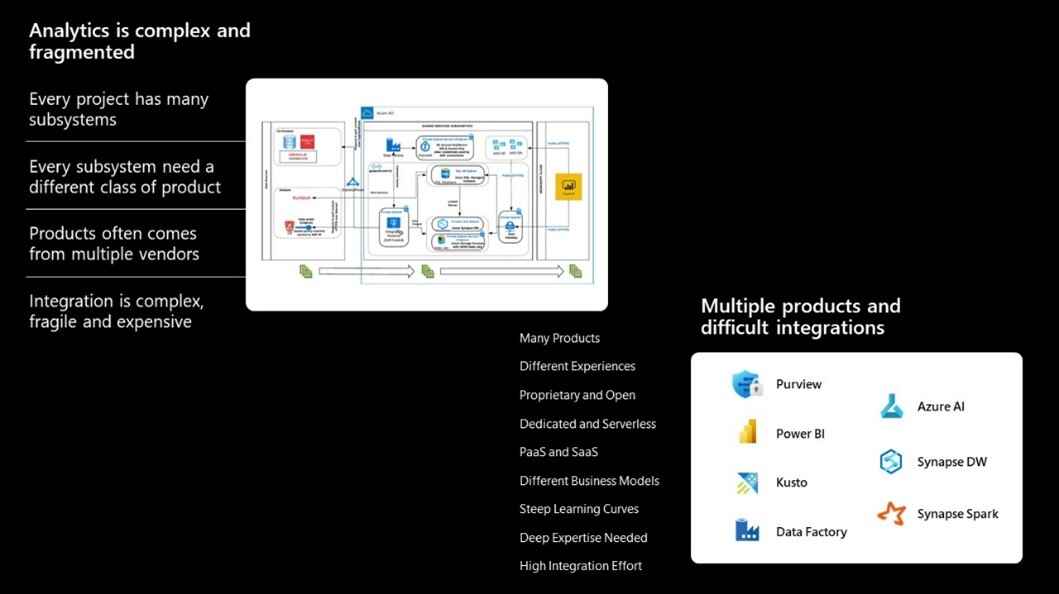
Not only multiple platforms need to be used for a range of activities from data warehousing, transformation, analysis, and visualization – but the complex integrations and connections between them take the difficulty up a notch.
With organizations increasingly realising the importance of data and with 91% of leaders reporting an increased investment in data and analytics1, the complexity of data management and integration is only going to increase. How to simplify this?
Enter Microsoft Fabric.
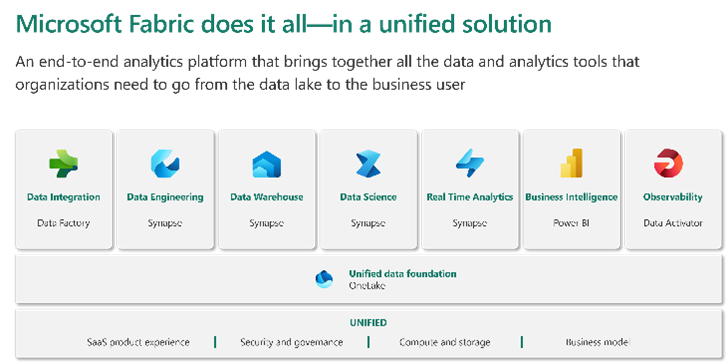
Microsoft defines Fabric as an all-in-one analytics solution for enterprises that covers everything from data movement to data science, Real-Time Analytics, and business intelligence.
In the words of Satya Nadella, it’s the best platform innovation since introducing the SQL server. Though it is probably too early to say whether it is true or not, it can be seen as a much-needed intervention to the growing integration complexities.
It’s not something that’s entirely new. For Kuroko no-basket fans, it’s like creating the team of Generation of Miracles (Vorpal Swords). Anyway, its purpose is to unlock the business value you expect and achieve more with less by unifying your hybrid and multi-cloud data estates for faster, connected intelligence. Here are a few advantages of using Microsoft Fabric as your data ecosystem:
100% SaaS-based
The idea of SaaS-ifying is to make things not too technical and more accessible to people who don’t need to worry about the hardware, infrastructure, or administration. As per Gartner’s research by 2026, 75% of organizations will adopt a digital transformation model predicated on the cloud as the fundamental underlying platform. The simplest way to explain this is that Microsoft Fabric is going to be as easy as establishing a Power BI workspace.
Lake-centric
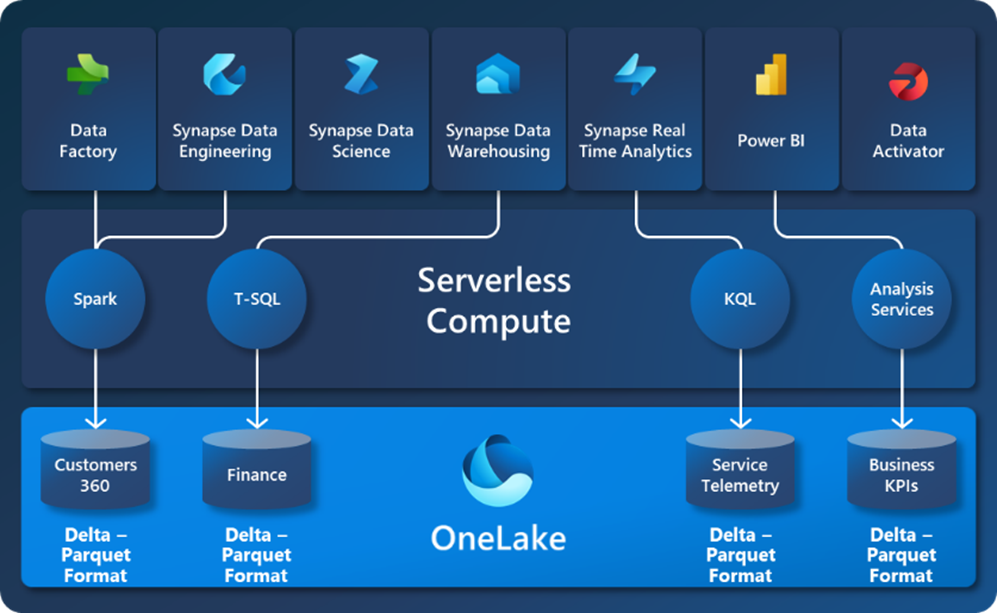
OneLake is the heart of Microsoft Fabric. It is the centralized repository where Fabric’s data and workloads are stored. It is a multi-cloud data lake where data from data warehouses and other data lakes is preserved in a common Delta Parquet format. This allows for all the Serverless Compute engines within Microsoft Fabric to be optimized and allows external resources to write data to your OneLake in an easily digestible format.
The simplest and the most common way to explain: OneLake is the Onedrive for your organization data. Once data is stored in the lake, it is directly accessible by all the engines without needing any import/export and is automatically indexed for discovery, MIP labels, lineage, PII scans, sharing, governance, and compliance.
Cost reducing
A few reasons why enterprise cloud costs spike are computing costs, data transfer, retrieval costs, integration, maintenance costs, etc.
With One Lake and Data fabric you can greatly reduce computational resource wastage and integration tax as multiple vendors are available under a single window and computational capacity can just be used by another workload.
You can also reduce the data movement on your platform thereby reducing costs as well as simplifying your data orchestration. And you don’t have to worry about data integration and maintenance since it is SaaS-based.
Empowering users across all domains
Microsoft Fabric is deeply integrated into Microsoft 365 to provide users access to data in real-time and from the same place. Additionally, each role is equipped with a suite of personalized analytics tools that help them independently generate real-time insights.
With a hub and spoke data mesh approach that overlooks workspaces and artifacts – you can analyze, blend, and transform data together without data movement.
Low-code & Pro-developer
In addition to having Low to No code, the Fabric environment provides value addition to developers. Spark-based functionality in VS code, Git integration, and notebooks with better collaborative features are a great addition. Compared to Synapse which takes roughly 3 to 4 minutes, in Fabric taking up Spark infrastructure would take roughly 20 to 30 seconds.
The idea of low-code is to augment the end-users to proceed with their analysis without the need for Synapse/Spark developers. It’s a win-win where developers can focus on the data, coding, and administration whereas the business users can perform their analysis.
AI-powered
With Azure Open AI integrated into Microsoft Fabric at every layer – users can leverage the power of Generative AI techniques wherever needed. With Azure Copilot users can build machine learning models, and data pipelines, generate code, and visualize results in conversational language. For example, Copilot can turn words into dataflows and data pipelines to help users integrate data from anywhere. For users writing code, Copilot can automatically suggest code and entire functions in real-time in their editor.
Seamless Integration
Fabric provides a unified centralized data repository (based on ADLS Gen 2) with data from multiple sources and platforms. Data from ADLS Gen 2, AWS S3, and Google Storage (coming soon) can be directly linked via a virtualization capability called “Shortcuts.”
Not only integrates with data lakes and data warehouses but it can also be seamlessly integrated with Microsoft 365 apps such as Excel, PowerPoint, Teams, Outlook, etc., and analytics platforms like Power BI.
In addition to these, as the entire architecture and data are based on Microsoft Security and governance is a given, we’re not talking about it in detail. Now that you understand the advantages that Microsoft Fabric provides, let’s dive into the components that we keep talking about and how all of these form a cohesive platform with Fabric.
Even before Microsoft Fabric, you could do data transformation and analysis with multiple Microsoft applications like Data Integration with Data Factory, Data Engineering with Spark, Data Warehousing with Synapse DW, Real-time Analytics with Kusto, Data Science with Azure ML, and Business Intelligence with Power BI.
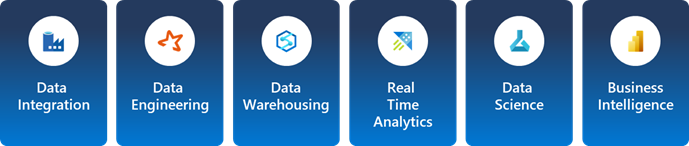
But the magic of Fabric is that you can do all this and add observability to the mix by leveraging three well-known players: Data Factory, Synapse, and Power BI – combined with a new player: Data Activator. If we continue our basketball analogy creating the – “Dream Team”.
Azure Data Factory: For a modern code-free, autonomous ETL data integration experience Data factory is used to ingest, prepare, and transform data from multiple data sources like databases, warehouses, data lakes, lakehouses, real-time data, etc. This is usually done with two primary high-level data factory implements namely data flows (to leverage more than 300 transformations) and data pipelines (to leverage the out-of-the-box rich data orchestration capabilities)
Azure Synapse: Microsoft Fabric uses Synapse environment for Data Engineering, Data Warehousing, Data Science, and Real-time analytics. This enables data engineers to transform data to support analysis based on Spark combined with a SQL-based data warehouse that fully separates compute from storage, enabling independent scaling of both components. For real-time observational data primarily in JSON or Text format with shifting schemas with Kusto Query Language, or KQL. For data science, you can start right from problem identification to gaining insights based on Apache Spark and Python for data preparation to SynapseML for massively scalable machine learning pipeline creation.
Power BI: There is no need to introduce what Power BI is. Even in 2016, they had more than 5 million subscribers – right now the number would have grown exponentially. With Power BI, users can build and scale a data hub across the entire organization with powerful visuals and analytics. Users can understand data, create reports, and share insights using conversational language and connect across multiple Microsoft 365 apps.
- Added value with Co-pilot: Users can simply describe the visuals and insights they’re looking for and Copilot will do the rest. Users can create and tailor reports in seconds, generate and edit DAX calculations, create narrative summaries, and ask questions about their data, all in conversational language.
Data Activator: For real-time stream processing through a system of detection that automatically alerts your team with relevant information. Data activator (currently under preview only) provides real-time data monitoring to coordinate human and automated actions like setting configurable alert conditions that automatically trigger responses across systems like teams, outlook, etc. all in a no-code experience.

“By 2026, 70% of organizations that successfully apply observability will achieve shorter latency for decision making, enabling competitive advantage” in the marketplace. Because of this, there is a great opportunity to build more mature data and analytics capabilities within––and across––your business.
Source: Top Strategic Technology Trends
After reading all this there might be a question in your mind. If all these existed before (excluding Data Activator), how is Microsoft Fabric different from existing platforms like Azure Synapse or Data Factory?
To elaborate on this, we’ll have to talk about two things: One, how this is different from Synapse, and two, how OneLake plays a major role.
Evolution from Azure Synapse
Instead of looking at both separately, Microsoft Fabric should be seen as the successor to Synapse (just like how Synapse was the successor of SQL Data Warehouse).
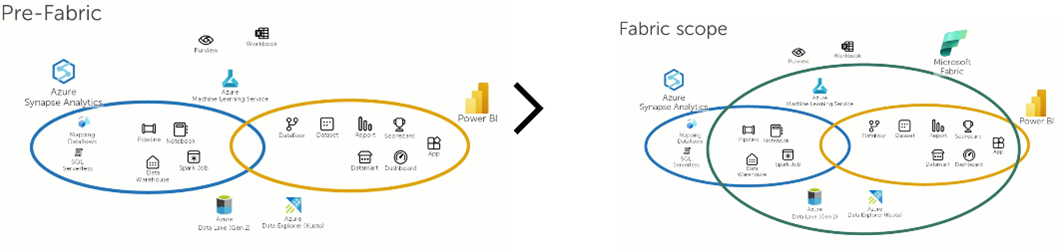
Here’s a direct comparison between the features of Synapse and Fabric:
| Existing Synapse Feature | Fabric Feature |
|---|---|
| SQL Serverless | SQL Endpoint |
| SQL Dedicated (SQL Data Warehouse) | Warehouse |
| Apache Spark Pools | Managed Spark Pools |
| Apache Spark Notebooks | Notebook |
| Apache Spark Jobs | Spark Job Definition |
| Data Explorer (KQL Scripts) | KQL Queryset |
| Data Explorer Database | KQL Database |
| Synapse Link | Not yet available in Fabric. |
| Synapse Studio | Replaced by new Power BI-based interface. |
| Git Integration | Git Integration |
| ML / MLOps | Data Science |
| Mapping Data Flows | Not supported by Fabric. |
| Pipelines | Data Pipelines |
We spoke about OneLake just a while ago, but we wanted to highlight the importance and how this seemingly small change is actually the backbone of Microsoft Fabric (and Microsoft Purview).
Some of the key features include:
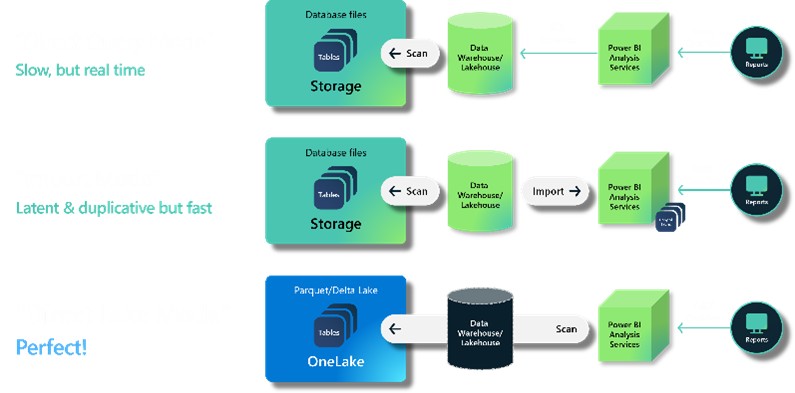
Source: Microsoft
In short, you can remove the integration issues between applications and have a data lake that has all the information i.e. Sharing data in OneLake is as easy as sharing files in OneDrive, removing the need for data duplication. In case there is any custom data/ application needed then with support for industry-standard APIs, it can be directly accessed.
Now to the final question.
Where to get started?
You can get started with a 60-day trial to Microsoft Fabric very easily with Power BI. In this Preview, you can get access to all the Fabric experiences and features with OneLake storage of up to 1 TB. You can read more about it here. Or you can just drop us a message and we’ll help you set up your Fabric process and guide you through all the features.
Synopsis: An all-in-one analytics solution with a SaaS foundation
Microsoft Fabric combines Data Factory, Synapse Analytics, Data Explorer, and Power BI into a single, unified experience, on the cloud. The open and governed data lakehouse foundation is a cost-effective and performance-optimized fabric for business intelligence, machine learning, and AI workloads at any scale. It is the foundation for migrating and modernizing existing analytics solutions, whether this be data appliances or traditional data warehouses.
1. Is there a direct upgrade/connector to move from Synapse to Fabric?
No, there is no direct upgrade path or connectors that can automatically migrate your data. To move your Synapse workloads onto Fabric, you will need to manually migrate and modify code including but not limited to notebooks, SQL scripts, and pipelines to enable it to run.
2. How does Microsoft Fabric handle data integration from multiple sources?
Microsoft Fabric provides seamless integration with various data sources, including databases, data lakes, cloud services, and even real-time streaming data by storing all the data in OneLake in Delta parquet format. This means users and apps can access data from the same place eliminating the need for import and export.
3. Is it mandatory for Azure Data customers to move to Microsoft Fabric?
No, Microsoft Fabric is not mandatory for customers who have an established Azure Data services footprint. Clients can decide to move their existing data architecture and services to Microsoft Fabric – but given the cost advantage and the efficiency it provides it would be a logical choice to upgrade or at least get the preview.
About Author

Data & BI Addict
When you theorize before data - Insensibly one begins to twist facts to suit theories, instead of theories to suit facts.
Related Blog
 Debadutta
Debadutta
