 LaliteshInformation Alchemist
LaliteshInformation Alchemist
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
Editor’s Note: In today's data-driven landscape, the significance of accurate and reliable information cannot be overstated. The financial implications associated with inadequate data quality are substantial and multifaceted. As highlighted by the costs outlined above, organizations must recognize that ensuring data accuracy from the outset (prevention cost) is far more cost-effective than rectifying errors after the fact (correction cost). The most alarming expense, however, stems from neglecting data cleansing altogether, resulting in significant operational setbacks and a steep failure cost.
Investing in robust data quality measures is not just a proactive strategy; it is an essential one. This blog underscores the importance of a comprehensive approach to data management, underscoring how prudent prevention can prevent higher correction and failure costs. By doing so, organizations can safeguard their resources, enhance decision-making, and fortify their competitive edge in an increasingly data-centric business environment.
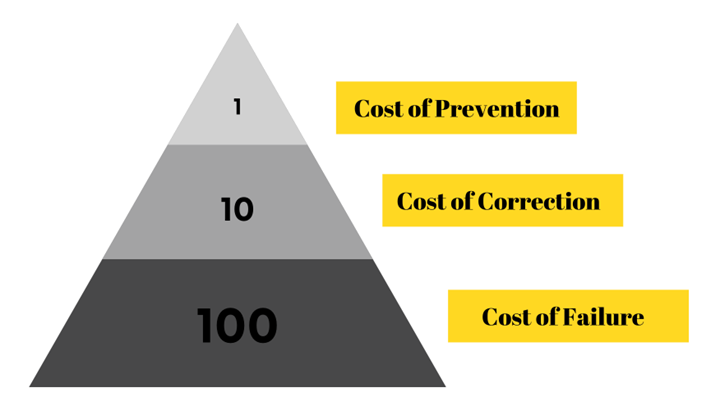
We have all been there, feeling that the data quality is not up to the mark. “Prevention is better than cure” is a saying that each of us has heard and resonates with that quote is the 1, 10, 100 rule that states that prevention is less costly than correction is less costly than failure.
Checking a record's quality costs $1 (prevention cost), cleaning and removing duplicates costs $10 (correction cost), and dealing with an uncleaned record costs $100 (failure cost).
There is a famous phrase that is widely used in the industry with context to data, is “Garbage in; Garbage out” implying that data models and engines/ forecasts are always as good as the data that is fed into the system.
Taking a reference from this IBM video on data Quality, imagine a restaurant, if the tomatoes they procured turned out bad and this was missed by the quality team as well, then the resulting food will also be contaminated with rotten tomatoes. Similarly, with bad data, all your subsequent aggregations, performance metrics, and even insights will be inaccurate.
If your team is suffering from “bad” data you're in the right place, let's look at what exactly could be termed as bad data, what are the reasons, how to spot it, what challenges it poses, how enterprises are tackling this problem and some future tech that might pave the way forward.
What not to do is as important as what to do, in some cases even more important, that is why it is prudent that a CIO, CTO, or any executive know how to catch “Bad/Poor Data.”
How to Spot Poor Quality Data
| Inconsistency: Varied formats and conflicting values. | Incompleteness: Missing or partial information. |
| Duplicates: Repetitive entries skewing accuracy. | Outliers: Data points significantly deviating. |
| Data sources and reliability: Unverified or uncertain origins. | Lack of context: Absence of necessary background. |
| Data validation errors: Invalid inputs impacting quality. | Data entry errors: Mistakes during input. |
| Data age: Information is outdated or irrelevant. | Data relevance: Not aligned with the purpose. |
Facts about Implications of Poor Data by Research
In today's data-driven landscape, the hidden costs of poor data quality can be staggering. According to HBR, knowledge workers waste a staggering 50% of their time in hidden data factories, grappling with data-related challenges like searching for information, rectifying errors, and seeking reliable sources.
This extends to data scientists as well, with 60% of their efforts spent on data cleaning and organization, as observed by CrowdFlower. Forrester's alarming discovery reveals that a mere 0.5% of available data is harnessed for analysis, with untapped potential costing businesses millions. Amid these struggles, the urgency to rectify poor data quality becomes clear. Gartner's recommendation of maintaining a 3.5 sigma value for data quality underscores the necessity of a mere 22,800 defects per million data points for accurate insights.
Delving further, Forrester reports that over a third of analysts invest over 40% of their time managing data issues. The unfortunate reality is that around 88% of data integration projects either fail entirely or face significant budget overruns due to subpar data quality.
However, Forrester estimates that a modest 10% enhancement in data accessibility could drive over $65 million in additional net income for typical Fortune 1000 businesses.
This mounting evidence underscores the imperative for businesses to prioritize data quality. It's not merely about avoiding errors; it's about leveraging data's true potential for informed decision-making and sustainable growth.
Reasons for bad data
1. Legacy Tools: Outdated or obsolete systems, software, or databases lack modern data quality controls, leading to data integrity issues. They might not integrate well with newer systems, resulting in data inconsistencies or errors.
2. Lack of documentation: While it is said that data ages like wine; data can decay when the accuracy and relevance of data diminish over time due to lack of documentation. This can happen due to quick changes in market conditions, outdated systems, or too much of people's dependency
3. Fragmented Data/ DataSilos: information that is spread across various sources, databases, or systems without proper integration. Data fragmentation can lead to duplicate entries and conflicting information.
4. Lack of Data Governance: Organizations that lack proper data governance policies and practices may struggle to maintain data integrity.
5. Poor Data Migration: Even during lift and shift processes, data can get corrupted or lost if not handled correctly.
6. Lack of Data Standardization: Inconsistent data formats/schema and naming conventions can lead to data integration challenges and inaccuracies. Building a Data Lineage is advised in such cases
7. Human Error: Mistakes made by individuals during data entry or data manipulation can introduce errors into the dataset.
Addressing these reasons for bad data requires a combination of technological solutions, organizational changes, and a data-centric culture that emphasizes the importance of high-quality data.
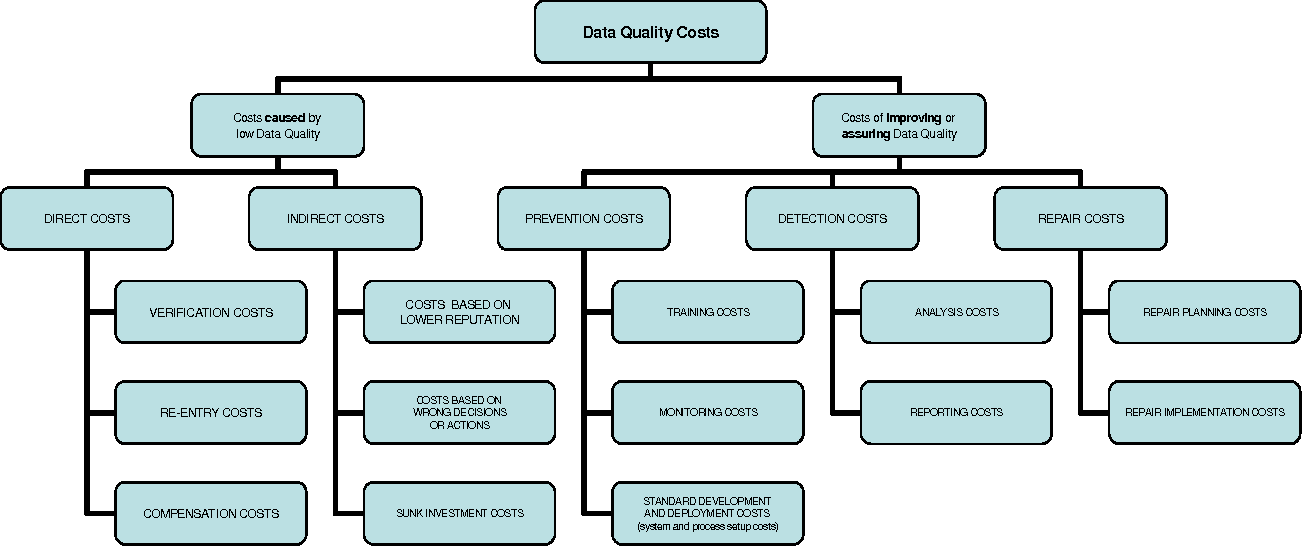
ResearchGate published a paper on “Classifying costs and effects of poor Data Quality – examples” by Tony O’Brien and Markus Helfert, although dated, the challenges and problems remain the same.
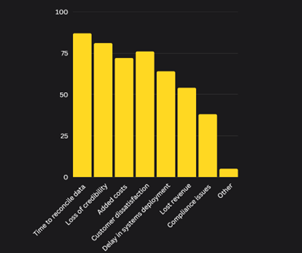
As shown in the table, time is one of the most important costs that arise due to improper data in your system, validated by multiple research organizations. It takes time out from your data team which could be spent on more meaningful tasks.

Let us consider the consequences of unacknowledged "bad" data and its impact on the entire system when data teams overlook this issue in the initial stages.
Downstream Impact of Bad Data
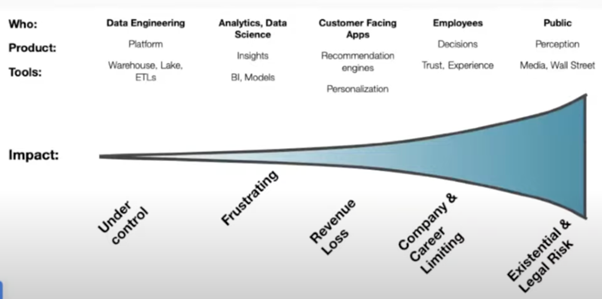
The degradation of customer data, at a rate of 2% monthly or 25% annually, coupled with inconsistencies, threatens business operations, and causes costly delays.
The Cost of Poor Data
Time Lost: explained via a real-life case
While we were involved in the FP&A (Financial Planning and Analysis) implementation for one of the largest BPO/KPOs in the world, we noticed something interesting: they had employed more than 50 chartered accountants who were primarily focused on compiling data in Excel. Instead of conducting analysis, they were engaged in manual data compilation/preparation tasks.
If their data had been clean and well-organized, their FP&A team could have been utilized more effectively. This wasn't an uncommon scenario – many data experts spend a substantial amount of time ensuring that data is accurate and organized. Wasting time translates to wasting money, and the inefficiency of not optimizing your team's potential remains a significant challenge. However, this situation can be resolved by having dependable and high-quality data readily available.

In the context of e-commerce, one notable aspect is the number of lost sales resulting from incorrect or incomplete information on product pages. When customers encounter inaccurate or insufficient details about a product they're interested in, their confidence in making a purchase diminishes.
Loss of Trust: Inaccurate or incomplete data erodes customer trust in the company's ability to provide reliable information, making customers hesitant to engage.
Missed Sales Opportunities: Customers who abandon a product page due to inadequate data represent missed sales opportunities for the company.
Customer Frustration: Frustration arises when customers can't find the information they need, leading to a negative emotional experience.
Negative Perceptions: Poor CX due to bad data can lead customers to perceive the brand as unprofessional, careless, or indifferent to their needs.
Reduced Customer Loyalty: Dissatisfying experiences lower customer loyalty, making customers less likely to return for future purchases.
Brand Reputation Damage: A pattern of poor CX due to bad data can damage the brand's reputation as customers share their negative experiences with others.
The evolution of big data has been driven by game-changing technologies like artificial intelligence (AI), machine learning (ML), and the Internet of Things (IoT). The advent of edge-to-cloud and streaming data necessitates adaptability and precision like never before. It makes storing data more economical and hence a lot of Dark data is generated that can pose a threat to data integrity.
Petabytes of data from Redshift, snowflake, and GCP can't be inspected by humans. It needs to be automated. Data is no longer stationary but a dynamic stream, demanding real-time management. This transition ushers in new challenges in sustaining data granularity and accuracy.
However, the complexity of developing in-house data cleaning solutions and the exorbitant expenses associated with acquiring packaged tools is a dilemma facing high-growth companies, according to this Talend blog.
The "chicken and egg" dilemma
To enable efficient AI programs, pristine data is paramount. Likewise, AI can facilitate the automation of data cleaning processes, ensuring that data maintains its integrity throughout. If data quality is not maintained at sufficiently elevated levels, ML algorithms will “learn poorly” and may develop a skewed interpretation of reality which will subsequently form the basis for automated decisions or recommendations.

* AI was unable to detect a dog as a dog and thought it was a tiger, implying data without context is just noise.
When we find an error, we usually simply correct it and move on without much thought. The problem is that errors recur, repeatedly. And they will do so until we do something about it. This brings us to the next point: Data Observability.
In order to check for poor data quality or poor data management, some key concepts of data observability are a must to keep in mind. These lay the foundation for building a robust data governance framework that should be tailor-made for your organization.
Our comprehensive data quality portfolio, including data enrichment, governance, integration, and a sophisticated sparse engine, empowers organizations to navigate the data landscape with confidence.
In the realm of Data Quality Management, our accelerators employ Pyspark to swiftly perform data quality checks across unstructured and structured data. This ensures a filtering process that eliminates duplicity and upholds the integrity of the data.
With an unwavering focus on autonomous business monitoring, the assurance of good data quality takes center stage, fostering accurate insights. Polestar stands ready to guide organizations through this journey, empowering them to harness the true potential of their data assets.
About Author

Information Alchemist
Marketeer at heart, story creator by passion, data enthusaist by profession.
Related Blog
 Debadutta
Debadutta
 Sudha
Sudha