 Ali kidwaiContent Architect
Ali kidwaiContent Architect
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
Editor's Note: In an age where innovation and technological advancements continuously redefine our world, the realm of data engineering stands at the forefront of transformation. The fusion of Generative AI not only reshapes the landscape of data but also propels us toward unprecedented possibilities. Our latest blog delves deep into this evolution, exploring the synergies between Gen AI and data engineering. As we navigate this intersection, we unearth groundbreaking insights into how AI-driven technologies redefine conventional data practices, opening doors to unparalleled efficiency and precision.
It’s inarguable that artificial intelligence (AI) and generative artificial intelligence (GenAI) have become central to tech conversations around how to do more with less. This is particularly true as organizations still struggle with limited budgets, a shortage of skilled talent, and the requirement to meet ever-changing consumer expectations. Sound familiar?
According to a survey conducted by KPMG, 77% of business leaders believe that GenAI will have the most significant impact on their businesses out of all emerging technologies. Additionally, 71% of these leaders plan to implement their first GenAI solution within the next two years.
Given statistics like these, CIOs are at the forefront of both the excitement and the pressure surrounding the unleashing of GenAI. But they are also neck deep in questions like, “What does this mean for my business?” and, “What risks do I need to contemplate?” Paramount among these vulnerabilities may be, “How do I navigate the noise around AI to empower my data engineering teams for success?”

Source: Decube
Today, 80% to 90% of the data we generate is unstructured, and the race to the top is faster than ever. This implies that data engineers face increased pressure to build and sustain dependable data pipelines, delivering valuable insights to their business stakeholders, which can be a source of frustration. However, Generative AI holds the promise to rebalance the scales in favor of creativity and inspiration.
So, without further ado let’s explore this blog where we'll highlight the possibilities of Generative AI reshaping the data engineering landscape.
Data engineering is the backbone of the modern data-driven world. It involves the extraction, transformation, and loading (ETL) of data from various sources into usable formats for analysis.
Traditionally, this process was labor-intensive, error-prone, and time-consuming. Moreover, as the volume and complexity of data continue to grow exponentially, the challenges faced by data engineers have become even more daunting.
Generative AI, particularly models like GPT-3 and GPT-4, has ushered in a new era for data engineering. These LLM models are trained on vast amounts of text data, enabling them to generate human-like text, making them exceptionally powerful in natural language understanding and generation tasks.
| Data Augmentation: Incorporation of Gen AI can be utilized to create synthetic data that augments existing datasets. Data engineers can use these synthetic datasets to train and improve machine learning models, enhancing their performance and generalization. | Automated Data Generation: Generative AI models, like GPT-3, can generate human-like text, making it easy for data engineers to create documentation, reports, and even code snippets. This can save a crucial amount of time and effort in the data engineering workflow. | Data Modeling and Schema Generation: Generative AI models can assist in generating data models and schemas automatically. This reduces the manual effort required in defining data structures and relationships, streamlining the data engineering process. | Natural Language Processing (NLP): It enables natural language interfaces that allow data engineers to interact with data systems using plain language commands. This simplifies data querying and retrieval, making data more accessible to non-technical users. |
ETL (Extract, Transform, Load) is a fundamental process in data engineering that involves extracting data from source systems, transforming it into a usable format, and loading it into a target data warehouse or database. Generative AI is revolutionizing ETL in the following ways:
Automated Code Generation: Generative AI models can generate ETL code, such as SQL queries or Python scripts, to perform data extraction and transformation tasks. This automation critically reduces the time and effort required to develop ETL pipelines.
Data Transformation Assistance: It can assist data engineers in designing data transformation logic. By providing descriptions or examples of the desired transformations, generative AI can generate code snippets or transformation rules, simplifying the ETL process.
Enhanced Data Quality: It can also identify and rectify data quality issues during the ETL process. For instance, it can generate code to clean and standardize data, reducing errors and ensuring high data quality.
Scalability and Efficiency: With Gen AI, data engineers can create scalable ETL pipelines that adapt to changing data sources and requirements. This flexibility improves data processing efficiency and ensures that insights are delivered promptly.
Therefore, this continuous improvement loop ensures that data pipelines evolve, adapting to changing data requirements and business needs.
Businesses can discover optimum potential through the right mix of technology. Here we are with various tasks where Gen AI can be incorporated into multiple aspects of their work:

1. Data Management
Data Quality Assurance: Gen AI can help automate data quality checks and flag issues like missing values, duplicates, and inconsistencies.
Data Cataloging: It can assist in automatically cataloging and indexing data assets, making it easier for data engineers to discover and access data.
2. Data Pipeline Development
Pipeline Orchestration: It can automate the orchestration of data pipelines, ensuring smooth execution of data workflows.
Auto-scaling can help automatically scale resources up or down based on workload demands, optimizing resource utilization.
3. Data Architecture Modernization
Data Lakehouse Design: Gen AI can assist in designing modern data lakehouses that combine data warehousing and data lakes, optimizing data storage and access.
Architecture Recommendations: It can offer recommendations for architectural improvements, such as adopting cloud-native solutions or microservices.
4. ETL & Data Transformation:
Code Generation: Gen AI can generate ETL code based on data transformation requirements, reducing the need for manual coding.
Data Mapping: It can assist in automatically mapping data sources to target schemas, streamlining data transformation processes.
5. Data Governance and Compliance:
Data Lineage Tracking: Gen AI can automate data lineage tracking to ensure data movement and transformations comply with data governance policies.
Security Auditing: It can perform automated security audits, identifying potential vulnerabilities and ensuring compliance with data security regulations.
However, using Gen AI tools in conjunction with human expertise is essential to ensure that automation aligns with business goals and regulatory requirements.

Source: Google
While Generative AI has the potential to automate many aspects of data engineering, it is essential to acknowledge that human input and manual intervention are still necessary in several scenarios:
Complex Requirements: Generative models may need help with complicated or ambiguous requirements. Data engineering often involves intricate business rules, data transformations, and data integration tasks that may require human expertise to define accurately.
Domain Specificity: Many data engineering tasks are highly domain-specific. Generative AI models may need more domain knowledge to generate code or schemas that align with specific industry standards or best practices. Therefore, human oversight is essential to review and validate the output generated by these models, especially in critical data engineering tasks.
Constraints in prompts: Generative AI models lack contextual understanding and may generate incorrect or incomplete code if the prompt is ambiguous or poorly structured. Data engineers must be crucial in providing clear and context-rich prompts to ensure that the generated code aligns with their intentions.
Data Privacy and Security: Data engineering frequently involves handling sensitive and confidential data. Generative AI models must be carefully controlled to avoid generating code or documentation that exposes sensitive information.
Quality Assurance: Human oversight is essential for quality assurance. While Generative AI can automate specific tasks, data engineers must review and validate the generated code, models, and documentation to ensure accuracy and reliability.
Unforeseen Scenarios: Data engineering often encounters unexpected scenarios or data anomalies that generative models may not cover. Human intervention is crucial for handling such situations effectively.
So, before wrapping up, let's navigate through several use cases of Generative AI that are gaining popularity, and even vendors of data products are directing their efforts to implement features like:
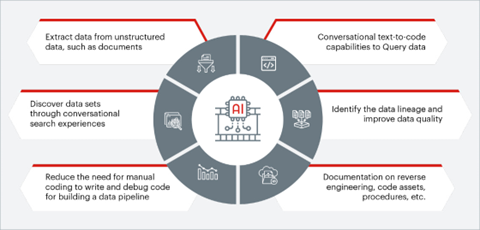
As we move forward, organizations that effectively leverage the synergy between Generative AI and data engineering will gain a competitive edge in the data-driven landscape. The future promises exciting possibilities for those who can harness the power of AI while upholding the highest standards of data quality and ethical use. Get in touch with us today to know more about our Data engineering services.
About Author

Content Architect
The goal is to turn data into information, and information into insights.
Related Blog
 Aishwarya Saran
Aishwarya Saran
.png) Aishwarya Saran
Aishwarya Saran