 DebaduttaSports and Tech Enthusiast
DebaduttaSports and Tech Enthusiast
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
Editor’s Note: The quest for the optimal cloud-based data warehousing solution is both cost-intensive and technically taxing. This analysis dissects the technical tapestries of AWS Redshift and Google BigQuery, offering an exploration of their architectures, functionalities, and suitability for diverse business needs. While there is a noize-fits-all concept when it comes to data warehouses, the blog aims to assist CXOs and decision-makers to establish linkages between their existing architectures and find the best alternative.
Data warehousing has evolved significantly in the past decade, thanks to the emergence of cloud computing and big data technologies. Cloud-based data warehouse solutions have become the preferred choice for many businesses, as they offer scalability, performance, cost-effectiveness, and availability. Moreover, the rise of hybrid and heterogeneous data architectures has become the norm.
Which component to use for a particular operation of the data engineering or analysis?
Do we need a cloud-based data warehousing solution or not?
How does each OEM play a pivotal role in a multi-cloud architecture?
These decisions are often daunting for CDOs as they have the potential to significantly impact the efficiency and effectiveness of an organization's data operations.
AWS Redshift, with its storage and Massively Parallel Processing (MPP) architecture, and Google BigQuery, with a unique columnar-based storage system, stand as two prominent players in this field, each offering a unique set of features and capabilities tailored for different use cases.
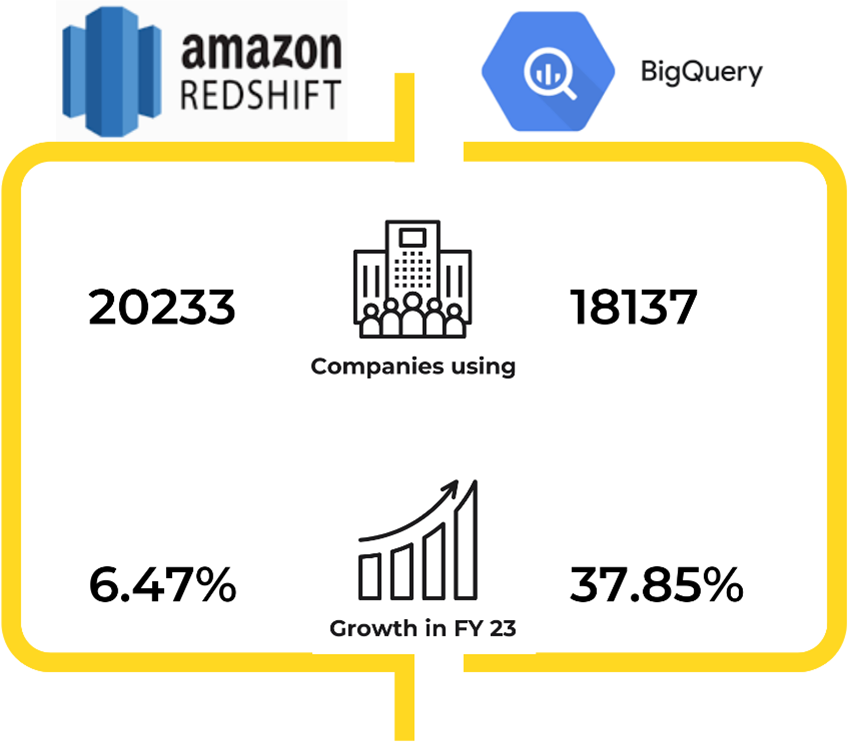
The global Data Warehousing Market size was valued at US$ 28.73 Bn. in 2022 and the total revenue is expected to grow at a CAGR of 10.7% from 2023 to 2029, reaching nearly US$ 58.54 Bn [1].
Architecture and Data Storage
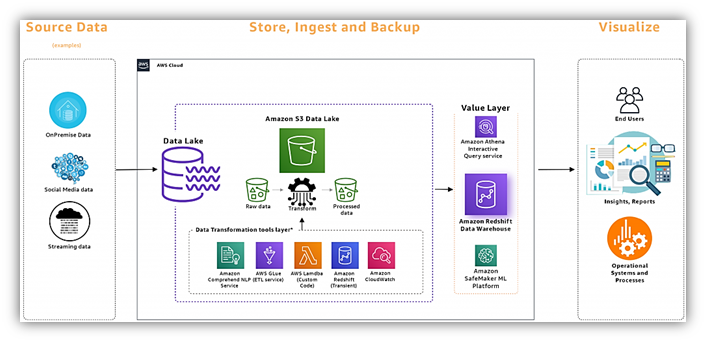
Amazon Redshift employs a columnar storage architecture, which organizes data by columns rather than rows. This design allows for highly efficient querying and aggregation operations, especially for analytics workloads. Additionally, Redshift operates on a cluster-based model, where multiple nodes collaborate to process queries. Data is distributed across these nodes, enabling parallel processing for enhanced performance.
Data Ingestion
Data ingestion in Redshift can be achieved through various methods including batch loading, direct querying, and data streaming. It seamlessly integrates with AWS Glue, allowing for efficient ETL processes. Redshift supports a wide range of data connectors and APIs, enabling smooth integration with various data sources. In performance tests, Redshift has demonstrated ingestion rates of up to 10 GBps
Advanced Analytics and Machine Learning Capabilities
Amazon Redshift provides a robust environment for advanced analytics and machine learning (ML) applications. It integrates seamlessly with popular ML frameworks such as TensorFlow and Apache MXNet. Additionally, Redshift Spectrum allows for querying data directly from Amazon S3, enabling data scientists to leverage the power of external data sources in their ML models.
Security and Compliance
Redshift provides a robust security framework, including features like encryption at rest and in transit. Access control is managed through AWS Identity and Access Management (IAM), allowing for granular control over user permissions. Redshift is compliant with various industry standards and certifications, providing a secure environment for sensitive data. Notably, Redshift has achieved certifications such as SOC 2, HIPAA, and PCI DSS.
Pricing and Cost Considerations
Amazon flexibility with no long-term commitments, while reserved instances offer significant cost savings for predictable workloads. Additionally, Redshift Spectrum allows for cost-effective querying of data stored in Amazon S3, providing a balance between performance and cost.
An enlightening exploration that will empower your business for years to come - Make the best choice for your data needs.
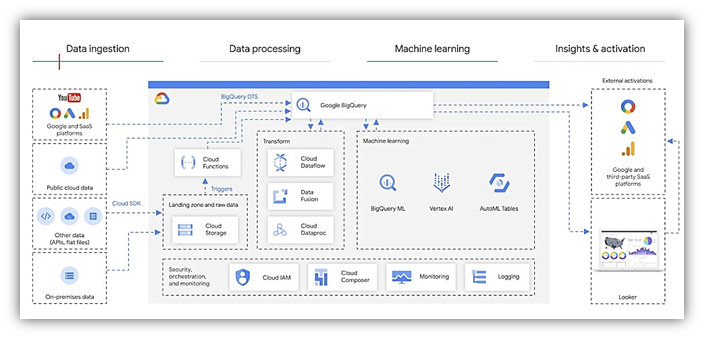
In contrast to the abovementioned competitor from Amazon, BigQuery on the Google Cloud Platform operates on a distributed storage system that allows for seamless scaling of computational resources as per demand. Data in BigQuery is stored in Capacitor, a custom storage format designed for efficient query execution. This architecture ensures that computational resources are dedicated solely to processing queries, leading to impressive performance gains.
Data Ingestion
BigQuery offers a plethora of ingestion options, including batch loading, streaming, and federated queries for querying external data sources. Its tight integration with other Google Cloud services simplifies data workflows. Additionally, BigQuery's support for standard SQL and compatibility with popular ETL tools ensures smooth data integration processes. BigQuery can handle streaming data at a rate of up to 100,000 rows per second per table.
Advanced Analytics and ML Capabilities
Google BigQuery offers a native ML service called BigQuery ML, which allows users to build ML models directly within the platform using standard SQL queries. This eliminates the need for data extraction and transfer to external ML tools. BigQuery ML supports a variety of model types, including linear and logistic regression, time series forecasting, and more.
Security and Compliance
Google Cloud platform has armed BigQuery with extensive security measures, including encryption of data both in transit and at rest. Access control is managed through Google Cloud IAM, allowing for fine-grained access policies. BigQuery is also compliant with numerous industry regulations, ensuring that it meets the strictest security and compliance requirements. BigQuery is certified with ISO 27001, SOC 2, and HIPAA, among others.
Pricing and Cost Considerations
BigQuery employs a pay-as-you-go pricing model based on usage. It separates storage and query costs, allowing for precise control over expenses. The distributed nature of BigQuery means that users only pay for the resources used during query execution, making it an economical choice for organizations seeking cost-effective data analytics solutions.
Amazon Redshift finds its niche in scenarios where high performance and complex analytics are paramount. It excels in data warehousing, business intelligence, and data science applications, particularly in organizations heavily invested in the AWS ecosystem.
Google BigQuery, on the other hand, shines in real-time data analytics and scenarios where rapid query execution is crucial. Its serverless architecture makes it an excellent choice for organizations looking for a low-maintenance, high-performance cloud-based data warehousing solution.
Amazon Redshift vs BigQuery: The Key Differences
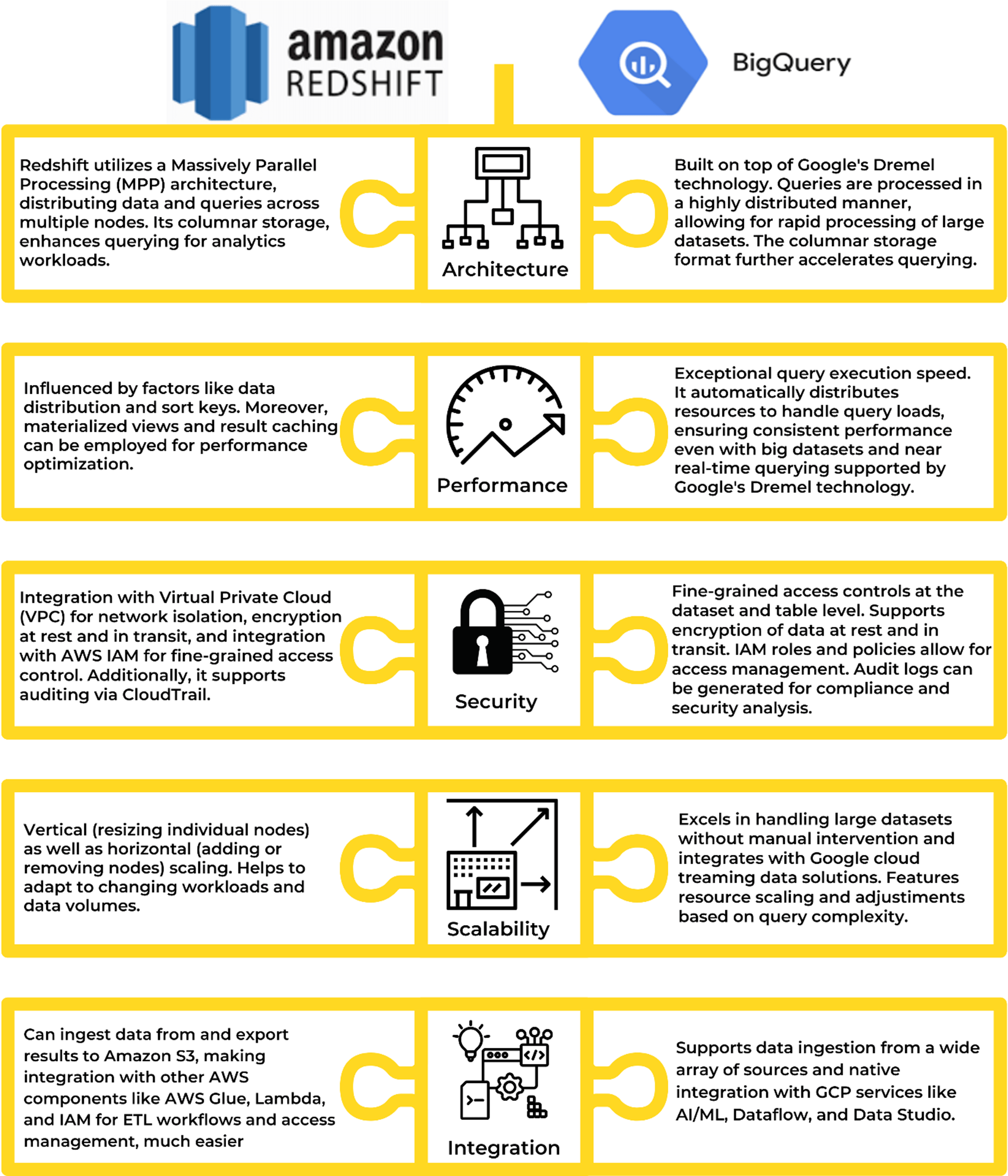
Overall Data Strategy: Despite having capabilities to work in a hybrid cloud system, for organizations with a well-entrenched AWS infrastructure, Redshift can slot in seamlessly – leveraging existing VPCs, IAM roles, and data lake integrations. Its native integration with services like AWS Glue for ETL and SageMaker for ML creates a cohesive data ecosystem. Conversely, BigQuery's multi-cloud compatibility positions it as a versatile player in heterogeneous or hybrid architectures. Its ability to query external data directly from cloud storage, coupled with its tight integration with Google Cloud AI/ML services, empowers organizations with diverse cloud footprints.
Expertise/Talent Availability: Beyond the platforms themselves, it's crucial to consider the expertise required to harness their full potential. Redshift leans heavily on SQL, making it a natural choice for teams versed in relational databases. Its integration with AWS ecosystem services like Glue, Lambda, and Kinesis demands a certain level of AWS proficiency. On the flip side, BigQuery's proprietary SQL dialect may be a comfortable adjustment for some teams, but its seamless integration with data lakes and Google Cloud's AI/ML services provides a learning curve.
Redshift vs BigQuery price comparison: In the current uncertain business scenario, one of the biggest factors for most businesses is the cost considerations. AWS RedShift price is a little easier to forecast pricing due to its on-demand, by-the-hour nature. But, in many business scenarios, BigQuery's $6.25/TiB query cost may make more sense. Amazon Redshift, with its columnar storage and cluster-based architecture, is tailored for organizations demanding high performance and scalability, especially those already entrenched in the AWS ecosystem. Google BigQuery, with its distributed architecture and pay-as-you-go pricing, offers a more customizable pricing and storage package – an effective solution for organizations seeking rapid query execution and seamless scalability.
Future Use Cases: The intersection of data warehousing platforms and ML is a space where the potential of Redshift and BigQuery come to the forefront. Redshift, with its MPP architecture, lends itself admirably to parallelized processing for ML model training. The elasticity and scalability of Redshift's clusters, coupled with GPU support, empower data scientists to tackle increasingly complex models. BigQuery, with its in-built ML functions, excels at quick, iterative model deployment and inference. The decision, therefore, hinges on the nature of your ML workloads - from intensive model training to real-time predictions.
Customer Segmentation and Personalization for a Retail Chain
AWS Redshift's Massively Parallel Processing (MPP) architecture is utilized to efficiently manage large datasets containing customer transaction histories, demographic information, and behavioral data. Through advanced analytics techniques like Singular Value Decomposition (SVD) or t-distributed Stochastic Neighbour Embedding (t-SNE), the retail chain performs intricate customer segmentation analyses. By integrating with machine learning frameworks like Apache Spark's MLlib or sci-kit-learn, the chain can develop personalized recommendation engines employing techniques such as collaborative filtering or content-based filtering.
Value Addition: This approach enables the retail chain to deliver hyper-personalized marketing campaigns, product recommendations, and promotional offers. By employing Redshift's computational capabilities and machine learning, the chain achieves higher conversion rates and increased customer loyalty.
Predictive Maintenance for a Manufacturing Plant
BigQuery's stream processing capabilities handle incoming sensor data from manufacturing equipment. Time-series analysis techniques utilizing Fast Fourier Transforms (FFT) or Wavelet Transforms are applied to detect patterns indicative of impending equipment failures. Machine learning algorithms integrated with BigQuery through platforms like Google AI Platform allow for the development and deployment of predictive maintenance models.
Value Addition: This technical approach enables the manufacturing plant to predict and schedule maintenance activities before critical equipment failures occur. By leveraging bigquery's real-time data processing capabilities and machine learning, the plant achieves significant cost savings through minimized unplanned downtime and increased operational efficiency.
The choice between Amazon Redshift and Google BigQuery ultimately hinges on the specific requirements and priorities of an organization. There are some differences, but there are far more similarities.
In conclusion, a thorough understanding of the technical nuances of each platform is crucial in making an informed decision. By aligning the strengths of Amazon Redshift or Google BigQuery with the specific needs of your organization, you can unlock the full potential of your data analytics endeavors.
About Author

Sports and Tech Enthusiast
In a world of opinions and cold numbers, data tells a compelling story.
Related Blog
.png) Aishwarya Saran
Aishwarya Saran
 Sudha
Sudha