 Shriya KaushikKhaleesi of Data
Shriya KaushikKhaleesi of Data
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
The data engineering landscape is undergoing its most significant transformation since the transition from batch to real-time processing. This change is marked by integration of AI.
By 2028, 75% of enterprise software engineers will use AI code assistants, up from less than 10% in early 2023.
This exponential growth isn't just about automation, it's about strategic repositioning as AI takes over tactical execution while elevating data engineers to higher-value strategic roles. With no further ado, let’s dive into the areas in data engineering that are seeing the biggest value and change with AI.
Data engineers often spend 57% of their time building and maintaining data sets; or their ELT/ETL pipelines, defining schemas, writing transformations, handling schema drift, and orchestrating workflows. AI-powered ETL tools are automating this process, rethinking how we approach data pipeline architecture.
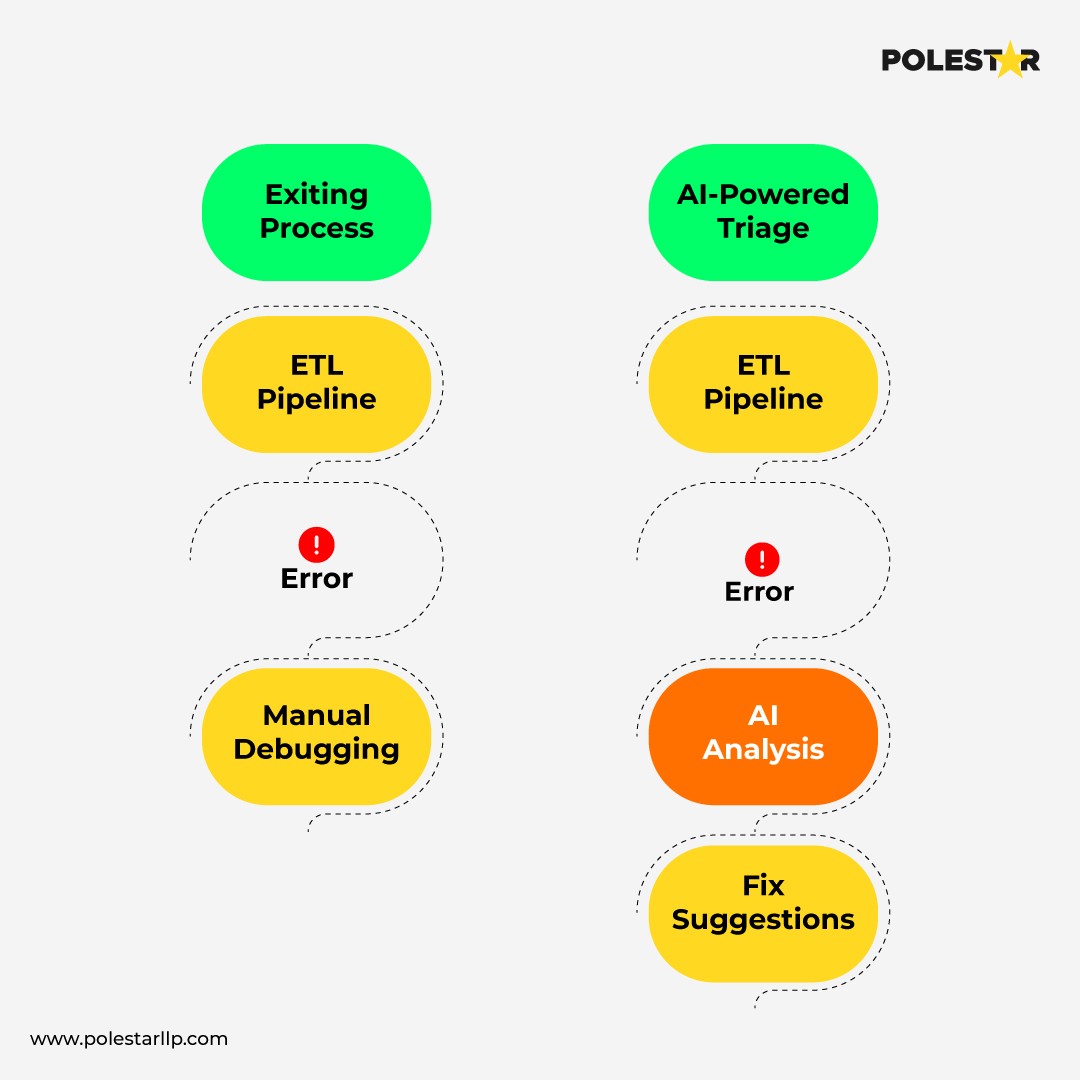
For data engineers, this means shifting from pipeline construction to pipeline curation and optimization. Low-code platforms like Data Nexus, take this further by offering a visual, component-driven interface to build and deploy AI-powered pipelines with minimal coding effort.
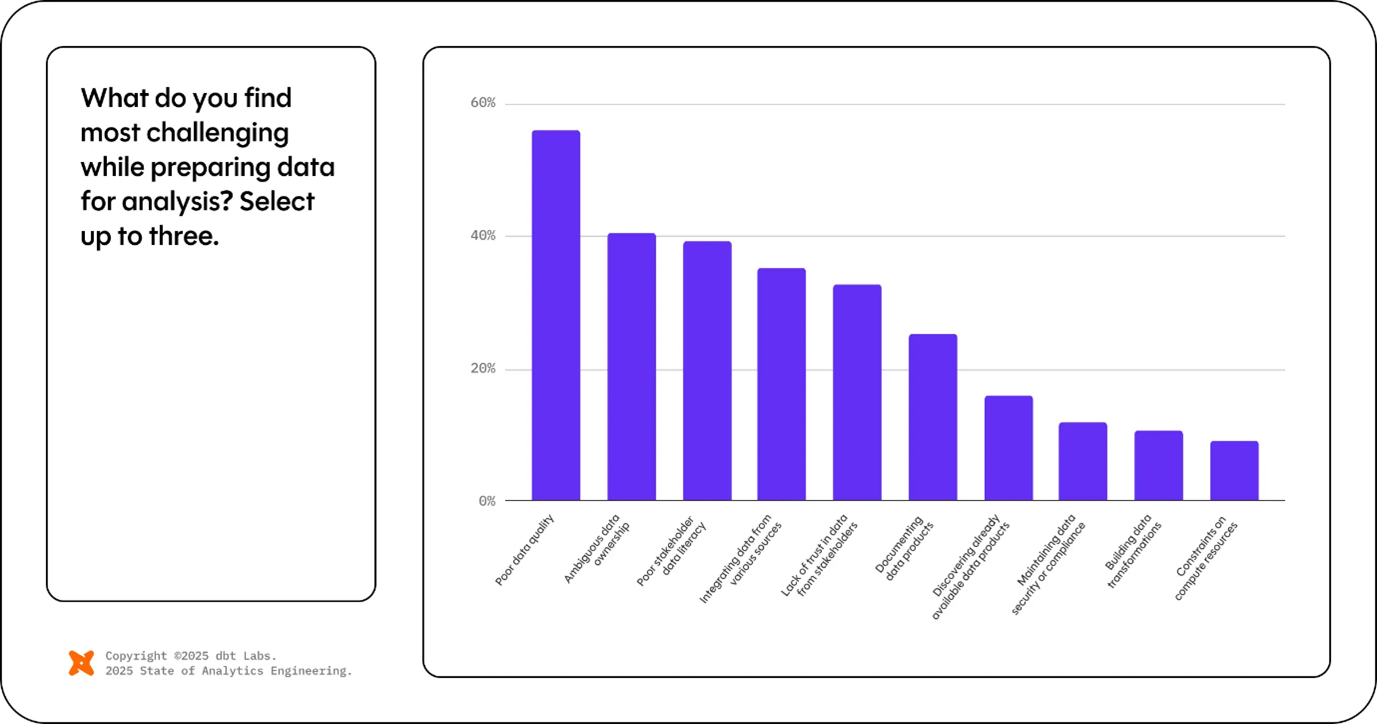
As you can see above data quality has always been the silent killer of analytics projects. Traditional approaches relied on manual rule-setting and reactive monitoring. AI-driven data quality solutions improve this by learning normal patterns and automatically flagging anomalies, inconsistencies, and data drift.
These intelligent systems establish baselines by understanding:
Instead of manually sifting through pipeline logs to figure out why yesterday's product catalog ingestion failed, intelligent anomaly detection systems automatically flag schema drift, such as a newly added nullable column, trace its downstream impact using data lineage, and surface contextual alerts explaining which model or dashboard might break. Some even suggest potential fixes, allowing engineers to address the issue proactively before it affects production.
Errors in your data pipeline architecture can have real costs, impacting not just computational resources but critical insights and downstream decisions. AI-driven orchestration platforms are evolving beyond simple task scheduling to predictive pipeline management with self-healing capabilities.
Some of the key AI highlights that are being developed in data orchestration systems are:
Pipelines automatically adjust resource allocation, reroute around problematic nodes, and trigger alternative processing paths, maintaining SLA guarantees and ensuring business continuity without manual intervention.
Ready to explore AI-powered Data Engineering solutions?What if your data catalog could automatically understand, tag, and govern every dataset in your organization while maintaining compliance requirements without human intervention?
Data governance has long been manual, time-intensive, and people dependent process. We can involve AI to ease the manual steps. For eg., AI-powered metadata management solutions are easing this process by automatically cataloging datasets, inferring relationships, and maintaining data lineage without human intervention.
To prove the point take a look at AI-powered Data Cataloging Features in Azure Purview
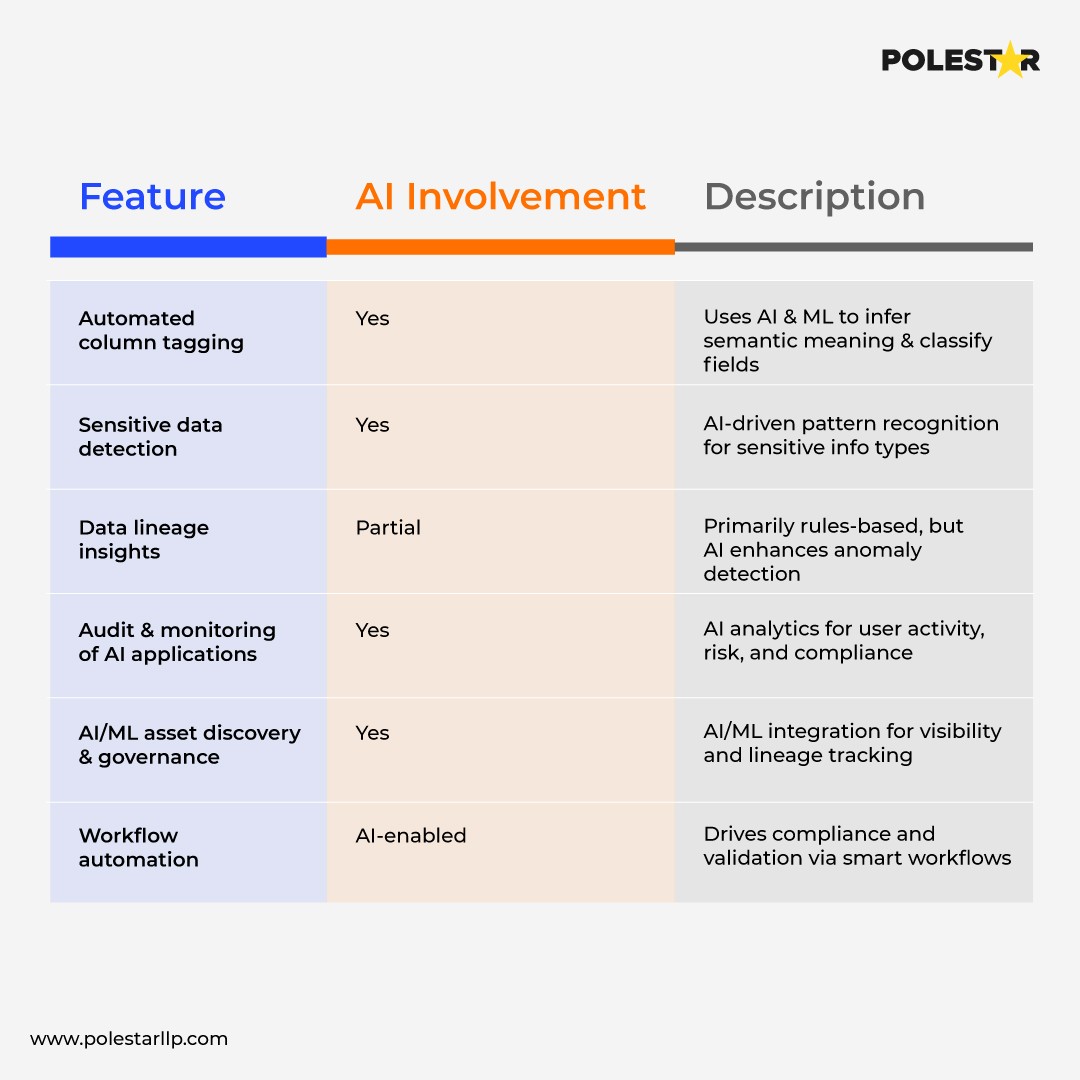
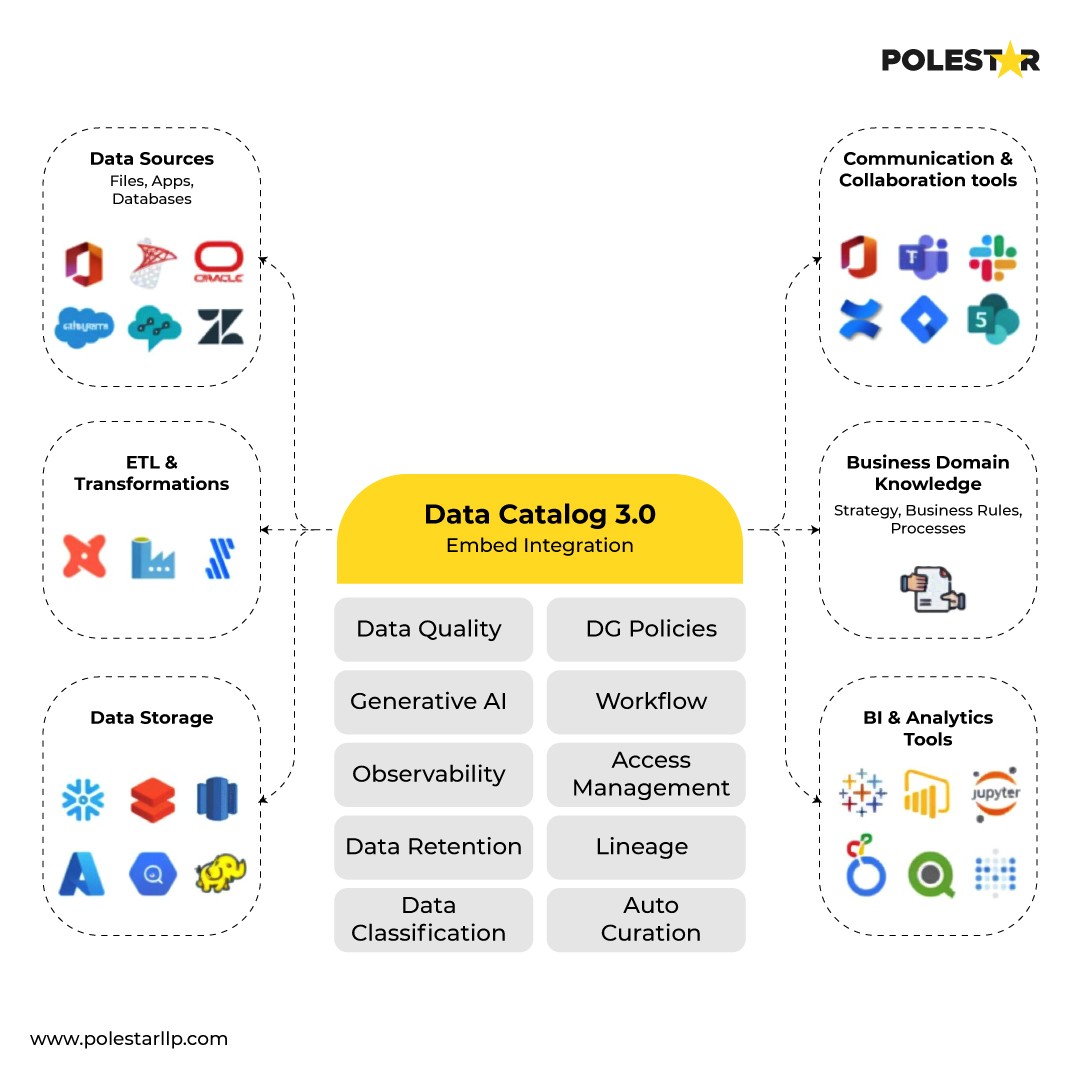
They can focus on architecting solutions rather than documenting them. The AI handles the repetitive work of maintaining catalogs, while engineers design better data architectures and governance frameworks.
For instance, a healthcare organization using Azure Purview can automatically classify patient data, maintain HIPAA compliance tags, and track data lineage across multiple systems—all while ensuring that sensitive data handling policies are automatically enforced throughout the data lifecycle.
Transform your healthcare data strategy with AI & Analytics solutionsAI Code Assistants are changing how data engineers develop, debug, and deploy pipelines. These tools can translate natural language instructions into production-ready SQL, PySpark, and complex data pipeline code.
They are accelerating prototyping, minimizing syntax errors, and enabling non-technical users to contribute to data solution design. These AI assistants also provide:
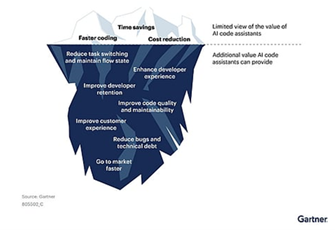
AI code assistants transform data engineers from code writers to solution architects, enabling focus on strategic business problems rather than syntax and implementation details.
Using AI code assistants like Databricks Assistant, you can describe: "Create a dimension table for customer data with Type 2 historical tracking, including effective dates and change tracking." The assistant generates the complete implementation, including merge logic, performance optimizations, and testing frameworks. Something like this:
While AI transformation offers immense potential, it's important to acknowledge that AI code assistants and automation tools are still in their nascent stage. Though the semantics are good, the contextual intelligence is growing. Some of the current limitations include:
P.S. AI coding assistants like any LLMs rely on public or huge codebases for training. Although the scale and scope is wide – the quality and reliability are not guaranteed., as the suggestions can based on outdated libraries or can give recommendations that violate best practices or security protocols or give duplicate code that may infringe on open source licenses.
However, these limitations are rapidly diminishing as AI systems become more sophisticated and context-aware.
The transformation of data engineering through AI isn't just an upgrade, it's a competitive necessity.
The data engineering lifecycle is evolving, and organizations that get on board with AI today will have competitive advantages. The question isn't whether to use these technologies, it's how fast you can roll them out to unlock new efficiencies and reimagine old workflows.
Hence, expert guidance to navigate this transformation effectively. Polestar Analytic’s Data Engineering provide the strategic framework and implementation expertise to harness AI's full potential while mitigating risks.
About Author

Khaleesi of Data
Commanding chaos, one dataset at a time!
Related Blog
.png) Aishwarya Saran
Aishwarya Saran
