
Want to see 40% reduction in infrastructure operational expense and a record decrease in data integration time?
Talk to our data engineering experts today
 Shriya KaushikKhaleesi of Data
Shriya KaushikKhaleesi of Data 
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
In today's competitive business environment, putting in place an Enterprise Data Warehouse is not merely an IT project—it is a strategic necessity. With day-by-day data generation increasing, which is likely to reach over 394 zetta bytes worldwide by 2028, you must ensure that Enterprise Data Warehousing system is prepared not only to support storage but rising demand for analytics.
You already know what it is. An Enterprise data warehouse (EDW) is like the Marie Kondo of your data landscape, making sense of disorganized chaos by aggregating information from disparate systems into a neat, analytics-supporting centralized repository. It is not merely another database it's an architectural solution to facilitate business intelligence functions and informed decision-making.
Early enterprise data warehouses (EDWs) were centralized. They used relational systems built on SQL databases with functions like SELECT, JOIN, and GROUP BY for processing historical reports and basic business intelligence.
Modern Enterprise Data Warehousing (EDW) services are distributed and cloud-based platforms. They use technologies like Massively Parallel Processing (MPP) databases, data lakes, and streaming ingestion that manages various data types- structured, semi-structured, and unstructured data. They also support real-time analytics, ACID transactions, complex SQL functions, and integration with AI/ML tools for making operational decisions, using ELT and data visualization.
But, let’s be honest, without efficient implementation, most enterprise data warehouses end up as nothing more than glorified storage systems.
What separates the high performers? It's rarely the technology itself, it's how they implement and evolve their enterprise data warehousing platforms through strategic best practices.
For gaining the most value out of your data warehouse, follow these five best practices with a logical implementation plan:
Best Practice: Establish measurable business outcomes before you even think about technology selection.
Most enterprise data warehouse implementations fail because they remain IT projects measured by uptime and query performance rather than business outcomes. Instead the strategy should start from a business outcome. For example, define specific, measurable outcomes such as:
Decision Velocity: Reducing weekly inventory planning cycles from 5 days to 2 days (requiring 2.5x efficiency gains), the rough estimate might look like this (Assuming 1 TB of current weekly data) – a 20-40% increase in computing power.
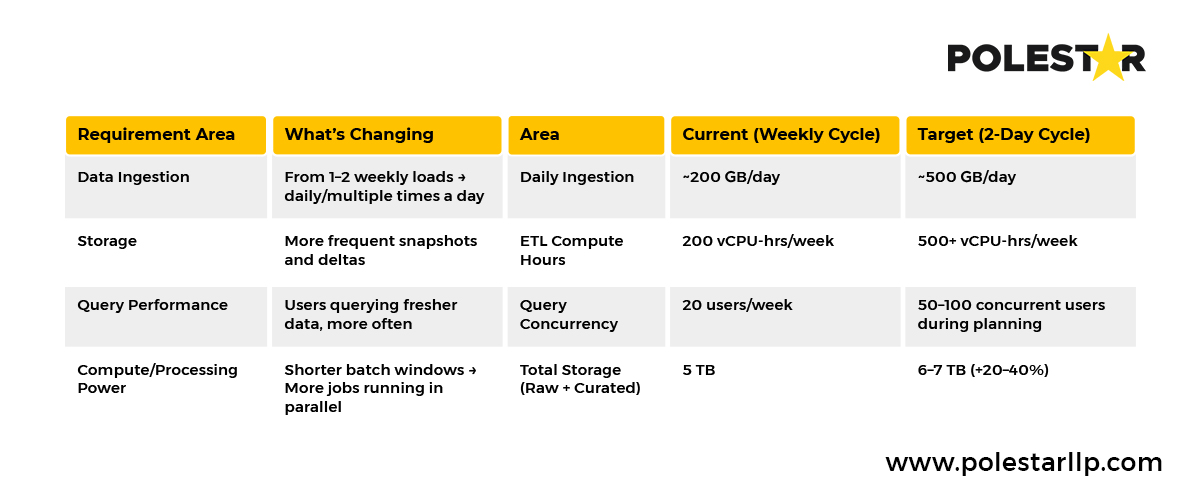
Whether your focus is customer retention, operational efficiency, or regulatory compliance, your Enterprise Data Warehouse optimization or characteristics should directly enable those outcomes through clear metrics.
Best Practice: Implement comprehensive data quality practices in the staging layer itself
Most data warehouses now have a staging environment that serves as your critical control point, between source systems and production EDW environments for data quality. But this isn't simply about data validation, it's about building systematic quality assurance that scales with your data volume and complexity. Some of the best practices to keep in this layer include:
| Area | Best Practice |
|---|---|
| Data Fidelity | Keep raw; no transformations |
| Loading | Append-only; timestamped |
| Partitioning | By date/source |
| Metadata | Store load timestamps, file names, batch IDs |
| Quality Checks | Lightweight validations only |
| Security | Encrypt + restrict access |
| Retention | Set expiry policies (e.g., 30–90 days) |
| Traceability | Enable lineage and batch tracking |
| Storage Format | Prefer columnar formats like Parquet/Delta |
P.S. These practices would be more specific when you go into the type like GCP, AWS, or Databricks. Eg: Applying vacuum policies (VACUUM Delta tables after 7–30 days) to reclaim storage, or enable data lifecycle management (DLM) if using Unity Catalog with cloud storage for Databricks implementation.
Practice: Hybrid integration approaches that match business velocity requirements
Enterprise Data Warehouse strategic value emerges from integrating diverse information sources into coherent business perspectives. Modern EDW implementations must support traditional batch processing for historical analysis while enabling real-time data flows for operational decision-making. Some of the common best practices that organizations today approach are:
- Implement intelligent pipeline orchestration
- Deploy advanced dependency management
- Implement auto-scaling pipeline execution
- Configure intelligent failure handling and monitoring
But to truly have the best data integration in the era of AI – you need to automate repetitive tasks like data extraction, transformation, loading, and model creation to improve efficiency and reduce errors. And we have one of the best solutions for that, Data Nexus!
Best Practice: Design OLAP engine within a 3-tiered Enterprise Data Warehouse architecture aligned with analytical consumption patterns
Your Enterprise Data Warehouse architecture determines organizational agility. So the most effective EDW implementations adopt three-tier architecture strategies balance performance requirements with business accessibility needs.

Processing Layer should be configured for OLAP engines based on specific analytical requirements and business requirements:
Modern platforms like Microsoft Fabric exemplify this flexible architecture with OneLake as the data repository, Synapse Data Warehouse for the OLAP layer (supporting HOLAP) capabilities, and Power BI for presentation—allowing organizations to leverage both data warehouse governance and data lake flexibility within a unified platform.
Practice: In addition to ensuring data lineage – meta data now should be able to facilitate LLMs and Agents
In the era of AI, metadata is no longer just a catalog; it’s the fuel for automation, lineage, governance, and intelligent discovery. Effective metadata management has evolved beyond technical documentation. Modern metadata approaches focus on business context alongside technical specifications, particularly as organizations prepare for AI and agentic workflows.
So, there are a few things to track wrt standardization, version control, the business context, and monitoring, like:

Additional best practices for meta data for agents and generative AI
New technologies, expanding data volumes, and changing business needs must all be accommodated by an effective enterprise data warehouse or even a modern lakehouse system. And for that, the next step in changing your data strategy is represented by Polestar Analytics' AI-driven data warehousing solutions!
A: Generative AI would transform Enterprise Data Warehouse operations in following areas:
Automated Data Preparation: AI generates ETL code, reducing development time while ensuring data quality standards. For example, AI can automatically create transformation rules when new data sources are added.
Query Generation: Business users can describe analytical needs in natural language, and AI generates optimized SQL queries, making it accessible to all. Automated Insights: AI monitors data patterns and generates business insights. It’ll alert respective stakeholders to anomalies without manual analysis.
A: Data Lakehouse is a hybrid data storage and processing platform that combines the best of both traditional data lake and data warehousing technologies: low-cost storage in an open format accessible by a variety of systems from the former, and powerful management and optimization features from the latter.
| Feature | Traditional EDW | Lakehouse Architecture |
|---|---|---|
| Data Types | Primarily Structured | All (Structured, Semi-structured, Unstructured) |
| Schema | Schema-on-Write (rigid) | Schema-on-Read/Write (flexible) |
| Agility | Less agile, difficult for new workloads | Highly agile, supports diverse analytics (BI, ML) |
| Cost | Often higher (proprietary) | Generally lower (open formats, cloud-native) |
| Governance/ACID | Strong ACID transactions & governance (built-in) | Adds ACID & governance to data lake (e.g., Delta Lake) |
A: A comprehensive Enterprise Data Warehouse system integrates four key elements:
Central Database: The architectural foundation implementing columnar storage optimized for analytical queries. Data Integration Tools: Sophisticated ETL/ELT pipelines that extract, transform, and load information, with modern platforms supporting real-time streaming and AI-powered data preparation.
Metadata Repository: Comprehensive documentation including technical specifications, business context, and operational metadata—increasingly enhanced with AI for automated classification and discovery.
Data Access Tools: Query interfaces, OLAP systems, visualization platforms, and AI/ML capabilities making information accessible across different user personas and analytical use cases.
About Author

Khaleesi of Data
Commanding chaos, one dataset at a time!
Related Blog
 Ali kidwai
Ali kidwai
Ali kidwai
Ali kidwai