
Last Updated : 05-December-2023
Editor's Note: As the realm of cloud data warehouses continues to evolve, innovations and changes may arise. In this blog, we've delved into the transformative capabilities of the best cloud data warehouses - Amazon Redshift, Google BigQuery, Snowflake, and the Azure Data Platform. These technologies stand as pillars in the realm of cloud-based data warehousing, each offering unique strengths and functionalities that cater to diverse business needs.
Data is the most crucial resource in any business today. A generic shift in business paradigm over the years has witnessed the role of storage and computation to empower the magnitude and intensity of the business modules.
Talking about storage, we all are aware of the data warehousing concept that provides businesses with the capability of slicing and dicing data to extract valuable insights from them to help in making precise and wise business decisions.
Also, a data warehouse acts as a central repository for all the data collected by any enterprise through various internal and external sources. It helps in reporting and data analysis.
Since the data warehouse feeds on data provided by different sources and mediums, including relational databases, NoSQL databases, or third-party APIs, the quotient of ambiguous data is exceptionally high. Thus, all the collected data needs to be combined into one single coherent data set and optimized to deliver quick solutions for critical database queries.
Earlier, the data warehouse was available only as on-premise solutions, which are mostly application-based, which made data warehouses challenging to expand.
So, observing the market needs, here we are with some of the robust data warehouse platforms.
Amazon Redshift

Amazon Redshift is a data warehouse product that forms part of the larger cloud-computing platform Amazon Web Services. It is a simple and cost-effective data warehouse solution that analyses all the user data across their on-premise data warehouses and data lakes.
Capable of delivering ten times faster performances than the traditional ones, Amazon Redshift embraces the power of machine learning, massively parallel query execution, and columnar storage on a high-performance disk. Users can easily set up and deploy a new data warehouse in a few minutes, and run queries across petabytes of data in the Redshift data warehouse and exabytes of data in their data lake built upon Amazon S3.
Now, let's look at the Amazon Redshift architecture. This section highlights the components of AWS Redshift architecture, thereby giving you enough pointers to decide if this is favorable for your use case. Below is the Redshift Architecture Diagram:
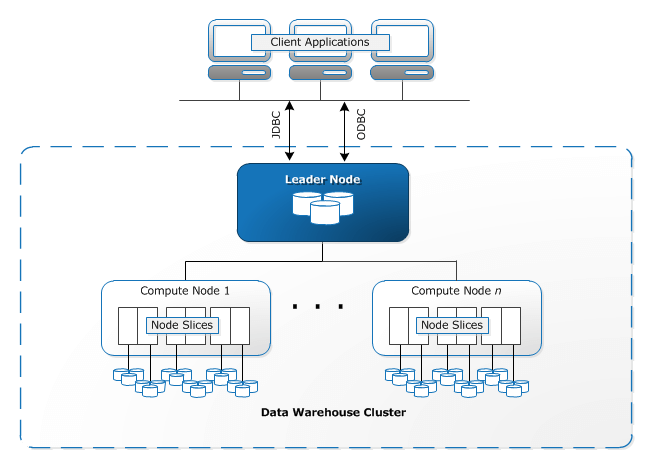
Credit: https://docs.aws.amazon.com/redshift/latest/dg/c_high_level_system_architecture.html
Redshift Cluster: Redshift uses a cluster of nodes as its core infrastructure component. A cluster usually has one leader node and several compute nodes. In cases where there is only one compute node, there is no additional leader node.
Compute Nodes: Each compute node has its own CPU, memory and storage disk. Client applications are oblivious to the existence of compute nodes and never have to deal directly with compute nodes.
Leader Node: The leader node is responsible for all communications with client applications. The leader node also manages the coordination of compute nodes. Query parsing and execution plan development is also the responsibility of the leader node. On receiving a query, the leader node creates the execution plan and assigns the compiled code to compute nodes. A portion of the data is assigned to each compute node. The final aggregation of the results is performed by the leader node.
Features
Massively Parallel
Amazon Redshift delivers fast query performance on datasets ranging in size from gigabytes to exabytes. Redshift uses columnar storage, data compression, and zone maps to reduce the amount of I/O needed to perform queries. It uses massively parallel processing (MPP) data warehouse architecture to parallelize and distribute SQL operations to take advantage of all available resources. The underlying hardware is designed for high-performance data processing, using locally attached storage to maximize throughput between the CPUs and drives, and a high bandwidth mesh network to maximize throughput between nodes.
Machine Learning
Amazon Redshift uses machine learning to deliver high throughout, irrespective of workloads or concurrent usage. It utilizes sophisticated algorithms to predict incoming query run times and assigns them to the optimal queue for the fastest processing. For instance, queries such as dashboards and reports with high concurrency requirements are routed to an express queue for immediate processing.
Automated provisioningAmazon Redshift is simple to set up and operate. You can deploy a new DW with just a few clicks in the AWS Management Redshift and the console automatically provisions the infrastructure for users. Most comprehensive tasks are automated, like backups and replication, so that you can focus on your data, not the administration. Redshift provides options to help you adjust to your specific workloads when you want to control them. New abilities are released transparently, eliminating the need to schedule and apply upgrades and patches.Fault-Tolerant
Amazon Redshift has multiple features that enhance the reliability of your data warehouse cluster. Redshift continuously monitors the health of the cluster, automatically re-replicates data from failed drives, and replaces nodes as necessary for fault tolerance.
Flexible querying
Amazon Redshift gives you the flexibility to execute queries within the console or connect SQL client tools, libraries, or Business Intelligence tools you use. Query Editor on the AWS console provides a powerful interface for executing SQL queries on Redshift clusters and viewing the query results and query execution plan (for queries executed on compute nodes) adjacent to your queries.
Google Bigquery

Google's BigQuery is an enterprise-grade cloud-native data warehouse. It was first launched as a service in 2010 with general availability in November 2011. Since its inception, BigQuery has evolved into a more economical and fully managed data warehouse that can run blazing-fast interactive and ad-hoc queries on datasets of petabyte scale. Additionally, BigQuery now integrates with a variety of Google Cloud Platform (GCP) services and third-party tools, which makes it more useful.
BigQuery is serverless, or more precisely, a data warehouse as a service. There are no servers to manage or database software to install. BigQuery service manages underlying software as well as infrastructure including scalability and high availability. BigQuery exposes a simple client interface that enables users to run interactive queries. It also has built-in machine-learning capabilities.
Now a dive into the Google Big Query Architecture.
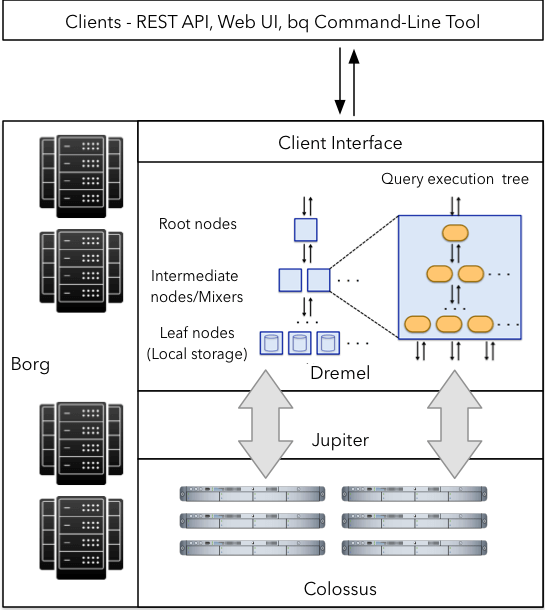
Credit: https://panoply.io/data-warehouse-guide/bigquery-architecture/
Dremel: Dremel is the query execution engine that powers BigQuery. It is a highly scalable system designed to execute queries on petabytes-scale datasets. Dremel uses a combination of columnar data layouts and tree architecture to process incoming query requests. This combination enables Dremel to process trillions of rows in seconds. Unlike many database architectures, Dremel is capable of independently scaling compute nodes to meet the demands of even the most demanding queries.
Colossus: Colossus is the distributed file system used by Google for many of its products. In every Google data center, google runs a cluster of storage discs that offer storage capability for its various services. Colossus ensures that no data loss of data is stored in the drives by choosing appropriate replication and disaster recovery strategies.
Jupiter Network: Jupiter network is the bridge between the Colossus storage and the Dremel execution engine. The networking in Google's data centers offers unprecedented levels of bi-directional traffic that allows large volumes of data movement between Dremel and Colossus.
Features
BigQuery ML
This helps experts such as analysts and scientists to build and operate ML models on different data structures with the help of simple SQL. After this, the models can be exported to the AI platforms for further predictions and other operations.
BigQuery BI Engine
One of the best features of BigQuery is its speed. It is pretty fast enables the users to analyze even the most complex data groups in just a few seconds and that too, with a higher level of accuracy. The BI Engine of BigQuery also helps integrate with different tools such as Data Studio and helps the experts in various data analysis and exploration.
Geospatial analysis with BigQuery GIS
BigQuery GIS specifically combines the serverless architecture of BigQuery with native support for geospatial analysis to can augment the analytics workflows with location intelligence. Simplify your analyses, see spatial data in fresh and ways, and unravel entirely new lines of business with support for arbitrary points, polygons, lines, and multi-polygons in standard geospatial data formats.
ML and predictive modeling with BigQuery ML
BigQuery ML gives data analysts and data scientists to build and operationalize Machine Learning models on planet-scale semi-structured or structured or data, directly inside BigQuery, using simple SQL—in a fraction of the time. Users can export BigQuery ML models for online prediction into Vertex AI or their serving layer with this feature.
Multi-cloud data analysis with BigQuery Omni
BigQuery Omni is a flexible, fully managed, multi-cloud analytics solution that gives users- securely analyze and cost-effective data across clouds such as Azure and AWS. Utilizing standard SQL and BigQuery’s familiar interface to quickly answer questions and share results from a single pane of glass across your datasets.
Connected Sheets
The users who are not available with the knowledge of SQL can still analyze a huge amount of data with the help of connected sheets of BigQuery. Different tools can be applied, such as charts, pivot tables, and many others, to extract insights from the data.
Apart from these many features, the warehouse is equipped with many others such as offering real-time analytics, offering logical data warehousing, materialized views, automatic backup, data transfer services, flexible cost models, high security, programmatic interaction, and many others.
Snowflake

Snowflake Inc. is a cloud-based data warehousing startup that was founded in 2012. Snowflake offers a cloud-based data storage and analytics service, generally termed "data warehouse as a service". It allows corporate users to store and analyze data using cloud-based hardware and software.
The Snowflake data warehouse uses a new SQL database engine with a unique architecture designed for the cloud. Snowflake has many similarities to other enterprise data warehouses but also has additional functionality and unique capabilities.
Let's know about Snowflake Architecture.
Snowflake's unique architecture consists of three essential layers:
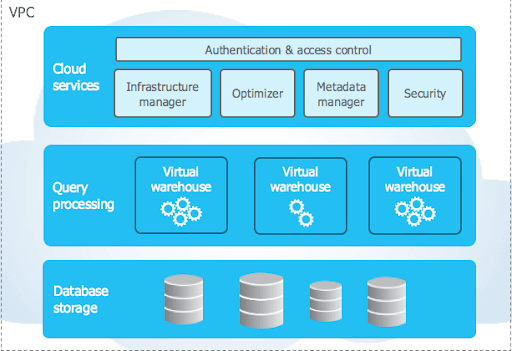
Database Storage
When data is loaded into Snowflake, Snowflake reorganizes that data into its internal optimized, compressed, columnar format. Snowflake stores this optimized data in cloud storage.
Snowflake manages all aspects of how this data is stored — Snowflake handles the organization, file size, structure, compression, metadata, statistics, and other aspects of data storage. The data objects stored by Snowflake are not directly visible nor accessible by customers; they are only accessible through SQL query operations run using Snowflake.
Query Processing
Query execution is performed in the processing layer. Snowflake processes query using "virtual warehouses". Each virtual warehouse is an MPP compute cluster composed of multiple compute nodes allocated by Snowflake from a cloud provider.
Each virtual warehouse is an independent compute cluster that does not share compute resources with other virtual warehouses. As a result, each virtual warehouse has no impact on the performance of different virtual warehouses.
Cloud Services
The cloud services layer is a collection of services that coordinate activities across Snowflake. These services tie together all of the different components of Snowflake to process user requests, from login to query dispatch. The cloud services layer also runs on compute instances provisioned by Snowflake from the cloud provider.
Features
Single Platform
One of the best features of Snowflake that it boasts quite often is the ability to perform different activities on a single platform. The users can perform a wide range of activities such as app development, drilling in the data lake, research by data scientists, and many others.
Secure Data
The warehouse offers the users to securely share the data to different parts of the enterprise or even to the customers without having the stress of security-related concerns. Whether structured data or semi-structured one, the user can share it even live without the worry of any kind of issues.
Scalability
Snowflake multi-cluster shared data architecture eliminates the storage and compute resources. This strategy allows users the ability to scale up resources when they require humongous amounts of data to be loaded faster and scale back down when the entire process is over without any glitches to the service. Users can start with an extra-small virtual warehouse and scale up and down as needed.
The user is provided with the facility of choosing different sets of infrastructure providers while Snowflake will take care of the data platform. The warehouse is known to be one of the best options for supporting the efficiencies of the business and the sovereignty of the data.
Security
From the manner users access Snowflake to how data is stored, Snowflake has a wide array of security features. You can manage network policies by whitelisting IP addresses to restrict access to the account. Snowflake supports numerous authentication techniques including support for SSO through federated authentication and two-factor authentication. Access to objects in the account is triggered through a hybrid model of discretionary access control (each object has an owner who grants access to the object) and role-based access control. This hybrid approach provides a significant amount of control and flexibility.
Recover Snowflake Object Using Undrop
This is one of the unique features that are native to Snowflake. You can recover the Snowflake object that is accidentally dropped. A dropped object can be restored using the undrop command in Snowflake, as long as that object is still in the recovery window.
Some Customers Of Snowflake
Azure Data Platform

Azure data platform is a cloud-based data integration service that allows you to create data-driven workflows in the cloud for orchestrating and automating data movement and data transformation.
It allows you to create data-driven workflows to orchestrate the movement of data between supported data stores and processing of data using compute services in other regions or an on-premise environment. It also allows you to monitor and manage workflows using both programmatic and UI mechanisms.
Using Azure Data Factory, you can create and schedule data-driven workflows (called pipelines) that can ingest data from disparate data stores. You can build complex ETL processes that transform data visually with data flows.
Additionally, you can publish your transformed data to data stores such as Azure SQL Data Warehouse for business intelligence (BI) applications to consume. Ultimately, through Azure Data Factory, raw data can be organized into meaningful data stores and data lakes for better business decisions.
SUGGESTED READ: DATA WAREHOUSE AND DATA LAKE CO-EXISTENCE FOR BUSINESSES
Now let's dive into the Azure Data platform architecture.
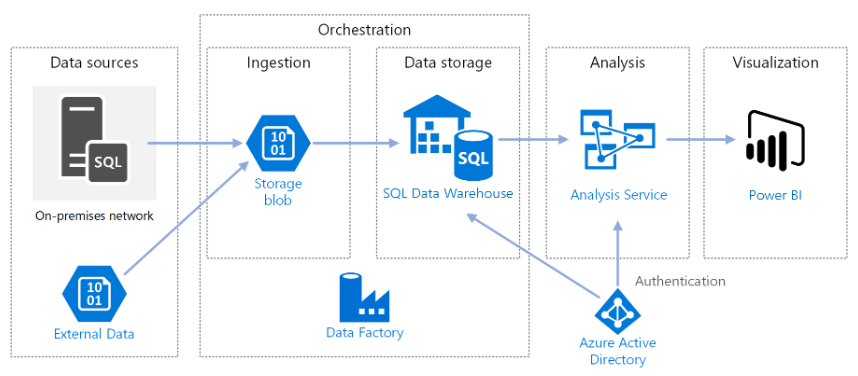
Data Sources
External data- A common scenario for data warehouses is to integrate multiple data sources. This reference architecture loads an external data set that contains city populations by year and integrates it with the data from the OLTP database. You can use this data for insights such as: "Does sales growth in each region match or exceed population growth?"
Ingestion and data storage
Blob Storage- Blob storage is used as a staging area for the source data before loading it into Azure Synapse.
Azure Synapse- Azure Synapse is a distributed system designed to perform analytics on extensive data. It supports massive parallel processing (MPP), which makes it suitable for running high-performance analytics.
Azure Data Factory- Data Factory is a managed service that automates data movement and data transformation. In this architecture, it coordinates the various stages of the ELT process.
Analysis and reporting
Azure Analysis Services- Analysis Services is a fully managed service that provides data modelling capabilities. The semantic model is loaded into Analysis Services.
Power BI- Power BI is a suite of business analytics tools to analyze data for business insights. In this architecture, it queries the semantic model stored in Analysis Services.
Authentication
Azure Active Directory (Azure AD) authenticates users who connect to the Analysis Services server through Power BI.
Data Factory can also use Azure AD to authenticate to Azure Synapse by using a service principal or Managed Service Identity (MSI). For simplicity, the example deployment uses SQL Server authentication.
Features
Data Resiliency
The very first thing that any enterprise looks for in any cloud data warehouse is security. In the case of Microsoft Azure, all the data is stored securely in the data centers of Microsoft. Microsoft Azure offers special extra security for the data if the users select from different security options that are available in the warehouse. This makes Azure be one of the safest cloud data warehouses and one of the reasons why more enterprises are opting for it.
BCDR Integration
Azure storage does not just offer security to the data but also makes sure to stay ready with any kind of data recovery operations. This means it also provides the right amount of Backup features for the data. Several customers and enterprises also make use of Microsoft Azure only because it can provide one of the top-class back-ups that supports the data.
Capacity Management
Capacity planning and management can be highly time-consuming. On the other hand, Microsoft Azure is featured with hybrid architecture in storage solutions. Under this feature, the warehouse offers numerous options such as archiving, data tiering, compression, and many others to manage the capacity well.
Single Pane Operations
Along with the other features that are offered by Microsoft Azure, another prominent feature that it offers is that of single pane operations. This helps the users in having better visibility of the insights and managing them better.
Some Renowned Customers Using Microsoft Azure
Conclusion
When data has become one of the essential elements of business, it is crucial to take care of it in the most efficient way. Having the right cloud based data warehouse is the perfect solution in such a case. Selecting the right platform can be a challenging task, but choosing the best provider can offer the right platform to enterprises.


