 Ali kidwaiContent Architect
Ali kidwaiContent Architect
Sign up to receive latest insights & updates in technology, AI & data analytics, data science, & innovations from Polestar Analytics.
Editor's Note: Understand how Data Mesh Architectures can remove the roadblocks from the central data team and bring a decentralized approach that enables teams to perform cross-domain data analysis themselves.
According to Gartner, only 20% of data analytics projects will deliver business outputs. Indeed, given that the current data architectures need to be better equipped to handle data's ubiquitous and increasingly challenging interconnected nature, this is not surprising. So, in a bid to address this problem, the question in every company's boardroom remains — how can businesses properly build data architecture to intensify data efficiency for the growing complexity of data and its use cases?
First defined in 2018 by Zhamak Dehghani, the data mesh concept is the latest approach to enterprise data architecture aiming to address traditional data platforms' pitfalls. Companies seeking a data architecture to meet their ever-changing data use cases should consider the data mesh architecture to power their business workloads and analytics.
Data Mesh is a relatively new approach to managing data in large, complex organizations. In simple terms, it involves breaking down data silos and organizing data in a more decentralized and collaborative way.
The idea behind Data Mesh is that data should be treated as a product, with ownership and responsibility distributed across the organization. Instead of having a central team manage all the data for the organization, each team or department is responsible for the data they create and use.
For example, let's say you work for a large e-commerce company. In the traditional approach, there might be a central data team responsible for managing all the customer data, product data, and transaction data for the entire organization. But with a Data Mesh approach, each department would be responsible for managing the data related to their specific area.
So the customer service department would be responsible for managing customer data, the product team would be responsible for managing product data, and the finance team would be responsible for managing transaction data. Each of these teams would create their own data products, such as a customer database or a product catalog, and make those products available to other teams within the organization.
By breaking down data silos and distributing ownership and responsibility, the idea is that data can be more easily managed and shared across the organization, which can lead to better collaboration, faster decision-making, and more innovation.
We help you deploy enterprise class solutions for your critical data to unlock the true potential of enterprise data.
Here's the table below that compares the features of traditional data management platforms to data mesh architectures.
| Traditional Data Management Platforms | Data Mesh Architecture |
|---|---|
| Serve a centralized data team that supports numerous domains | Serve autonomous domain teams |
| Manage code, policies, and data as a single unit | Manage code and pipelines independently |
| Needs separate stacks for operational and analytical workloads | Offers a single platform for operational and analytic workloads |
| Centralize the platform for optimized control | Decentralize the platform for optimized scale |
| Force domain awareness | Remain domain-agnostic |
Rather than taking data as a centralized repository, a data mesh's decentralized nature allows data ownership to domain-specific teams that control, manage, and deliver data as a product, allowing easy accessibility and interconnectivity of data across the business.
Today numerous organization' data use cases can be split into analytical and operational data. Operational data represents data from the organization's applications' day-to-day operations. For example, using an e-commerce store will mean customer, transaction, and inventory data. This operational data type is generally stored in databases and utilized by developers to create various APIs and microservices to power business applications.
Operational vs. analytical data plane
On the other side, analytical data represents historical enterprise data utilized to enhance business decisions. In e-commerce stores for instance, analytical data answers ques such as "how many consumers have ordered this product in the last few years?" or "what products are customers likely to purchase in the winter season?" Analytical data is typically transported from multiple operational databases using ETL techniques to centralized data stores such as - warehouses and data lakes. Data analysts and scientists utilize it to power their analytics workloads, and marketing and product teams can make impactful decisions with the data.
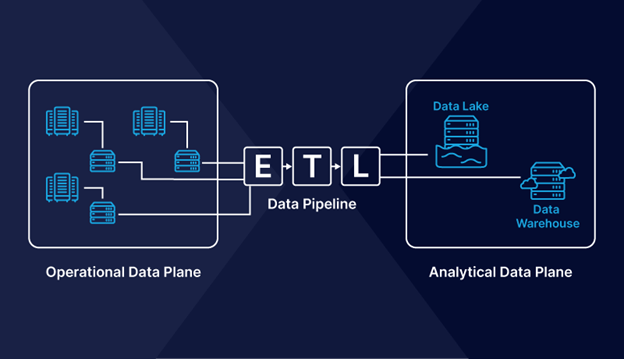
A data mesh approach understands the core difference between the two broad types of data and tries to connect these two types of data under a different structure — a decentralized approach to data management.
Have a look at Microsoft's offering Azure Synapse Analytics, along with both Data Lake Storage Gen2 and SQL database, as the central components for implementing a data mesh architecture.
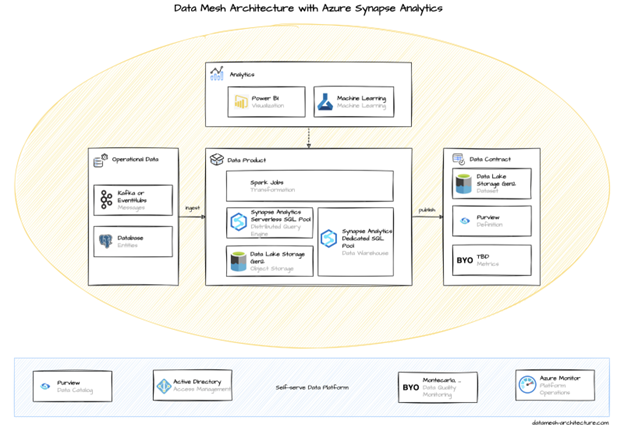
A data mesh framework is based on four principles that change the way data analytics are enabled in the enterprise:

Domain-driven ownership and architecture
The foremost principle of a data mesh is shifting the power of ownership and data into the hands of the domain teams. They own the data end to end—from ensuring they have the apt sources or ingested data to work with, to maintaining and building any processing pipelines mandatory, to serving the data out for other domain teams to tap into as products (more on that later) with the excellent quality guarantees and governance controls in place. The domain teams can be defined by the department, business unit, or other similarly motivated groupings. If they are correctly implemented, new domain teams should be able to be added fluidly and significantly when data is being correlated into new data products.
Data as a product
As alluded to in the first principle, domain teams are not just responsible for the data and the resulting data products. And data products require to be treated like any other product. Consumers and other domain teams need to discover and use data products. The domain owner is responsible for maintaining and updating (or deprecating) these products to make sure accuracy and quality. What can this look like in practice? Imagine a supply chain team curating an inventory data product that marketing folks can tap to develop new discount campaigns or that can be utilized by regional teams for placing new orders.
Self-service infrastructure
The third principle is making all this self-service easy for the domain teams. Complex technologies and niche skills are not sustainable in a data mesh design. There requirement to be a common platform and set of tools that any domain team can indulge in to serve and build their data products without getting bogged down in infrastructure resource or maintenance limitations.
Federated governance
The last piece of a successful data mesh is governance. A data mesh architecture can't come at the expense of access controls and data protection. There must be a balance between global governance policies and controls and ensure each domain team can define and implement these policies when developing and sharing their data products. This federated governance is critical for ensuring data privacy and compliance and aiding discovery at scale.
Combined, these principles enable a decentralized yet robust and extensive data framework designed to deliver business outcomes. The resulting analytical data architecture and operating model treat data as a product that can be owned by the teams with the most intimate knowledge of their consumption and analytics needs.
Now, have a look at some of the significant benefits of Data Mesh in the image below.

Implementing a data mesh can effectively improve your organization's access to and control of data. However, it is crucial to consider the best practices for implementation to ensure you get the most out of this technology.
Hence, by following these best practices for implementing a data mesh, you can make sure that your company has the right infrastructure, goals, and needs to build an effective data mesh solution.
Our approach can help you to ingest, enrich, transform, and serve data via a centralized platform.
While distributed data mesh architectures are still gaining adoption, they're helping teams attain scalability goals for common big data use cases. These include:
Business intelligence dashboards: As new initiatives arise; teams commonly require customized data views to understand the performance of these projects. Data mesh architectures can support this need for flexibility and customization by making data more available to data consumers.
Customer experience: Customer data allows businesses to understand their users better, allowing them to provide more personalized experiences. This has been observed in various industries, from marketing to healthcare.
Machine learning projects: By standardizing domain-agnostic data, data scientists can more easily stitch together data from numerous data sources, reducing the time spent on data processing. This time can accelerate the number of models which move into a production environment, allowing the achievement of automation goals.
As businesses collect, store, and analyze more data, decentralized data ownership becomes evident. Ultimately, putting data back into the hands of those who understand is the way to go. Developing a distributed self-service architecture with centralized governance necessitates ongoing dedication.
Transitioning from a monolithic to a distributed model necessitates enterprise reorganization and cultural shifts. However, the effort is worthwhile because this transformative paradigm has the potential to boost an enterprise's data-centric vision.
Polestar Analyticsis a leading IT consulting firm that has helped numerous organizations to transform their data operations. Data generation is increasing exponentially, and access to monolithic data sets becomes harder with time. Book a consultation today!
About Author

Content Architect
The goal is to turn data into information, and information into insights.
Related Blog
 Shriya Kaushik
Shriya Kaushik
 Bhaskar Pathak
Bhaskar Pathak